

1. 서 론
아스팔트포장은 교통시설의 핵심요소로 콘크리트포장에 비해 시공이 용이하고 차량 주행 시 발생하는 소음과 진동이 적어 도로포장에 널리 이용된다. 그러나 아스팔트포장은 그 재료의 특성으로 인해 콘크리트보다 강도가 낮아 더 많은 유지관리 비용이 소요된다. 따라서 공용중인 아스팔트포장의 품질상태를 정확하게 평가하는 것은 안전한 교통환경 조성을 위해 매우 중요하다.
아스팔트포장의 품질평가는 아스팔트 코어채취를 이용한 역학적 특성 평가를 통해 이루어지는 것이 보통이나 최근에는 비파괴기법 중 하나인 지표투과데이터(ground penetration radar, 이하 GPR)를 이용하여 원위치에서 포장체의 품질평가가 널리 이용된다. GPR은 전자기파를 매질에 방사하여 내부나 층 경계면에서 반사되는 전자기파를 수신하는 방식으로 매질상태를 정성적으로 평가하는 기술이다. 반사파의 속도와 진폭을 이용하여 매질의 구조 및 물리특성을 평가할 수 있으며, 이 반사파 특성은 매질이 갖는 고유의 유전율과 밀접한 관련이 있다(Davis et al., 1994). 따라서 GPR 탐사를 통한 아스팔트포장 품질평가를 위해서는 포장체 유전율에 대한 올바른 이해와 분석이 요구된다.
기존연구에서 아스팔트-골재의 비율, 골재의 종류와 크기, 함수량 및 밀도가 아스팔트포장의 유전율에 미치는 영향이 연구되었다(Lau et al., 1992; Davis et al., 1994; Shang et al., 1999; Shang and Umana, 1999). 또한, Shang(2002)은 이러한 영향인자를 고려하여 아스팔트의 유전율을 평가할 수 있는 다중선형회귀모델을 제안하였다. 본 논문에서는 기존문헌의 데이터를 이용하여 support vector machine(SVM) 기반의 아스팔트 유전율 예측모델을 제시한다.
2. 배경이론
2.1 유전율
유전율(permittivity)은 외부에서 전기장이 작용할 때, 물질이 저장할 수 있는 전하량을 나타낸다. 일반적으로 물질의 유전율은 실제 유전율을 진공 유전율로 나눈 상대유전율(relative permittivity)로 표현된다(Shang and Umana, 1999). 물질의 유전율은 주파수에 따라 변하는 주파수 의존성을 갖기 때문에, 이는 외부주파수 ω에 대한 복소함수(식 (1))로 나타난다(Kneubuhl, 1989).
여기서 는 복소상대유전율(complex relative permittivity), 와 는 각각 복소상대유전율의 실수부와 허수부로 유전상수(dielectric constant)와 손실계수(loss factor), i는 허수 단위 (), ω는 각주파수이다. 실수부는 물질 내에서 분극으로 인한 전기에너지를 저장하는 능력을 나타내고, 허수부는 열로 인한 에너지손실을 나타낸다. 따라서 상대유전율의 두 요소는 주파수에 따른 에너지의 저장능력과 손실 정도를 의미한다.
2.2 Support Vector Machine
Support vector machine(SVM)은 초기에 분류문제를 해결하기 위한 방법으로 제안되었으나, 오류둔감 손실함수의 도입으로 회귀문제에 적용이 가능하다(Cortes and Vapnik, 1995; Vapnik et al., 1996). SVM regression(SVR)은 데이터 분포를 근사하는 함수 또는 초평면(hyperplane)을 찾는 것이며, 이는 데이터 집합에서 발생하는 오차(e)를 최소화하는 구조적 위험 최소화(structural risk minimization) 원리에 기초한다(Smola and Schölkopf, 2004).
SVR은 학습데이터 집합에서 특정 범위의 분산을 가지는 선형목적함수 를 추정하는 것이며, 변수 w, x, b는 각각 가중치벡터, 데이터벡터, 절편이다. 최적의 선형목적함수는 특정 범위의 분산에 최대한 많은 데이터가 포함되도록 하는 최적화를 통해 얻을 수 있다. 이를 위해 데이터 집합의 경계에 있는 데이터를 support vector로 정의하고 함수의 추정과 최적화를 진행한다(Smola and Schölkopf, 2004). 한편, 데이터 오차를 반영하기 위해 여유변수(slack variable, )를 도입하여 e만큼을 벗어난 데이터를 고려한다(식 (2), (3)).
여기서 상수 C는 모델 복잡도와 학습오차 간의 균형을 조절하는 페널티변수로서, 모델이 과적합(overfitting)을 제어하는 값이다. 일반적으로 C값이 클수록 학습데이터에 의한 오차가 감소하도록 모델이 학습되나 높은 복잡도를 지닌다.
Fig. 1은 오류둔감 손실함수와 여유변수를 사용한 SVR 비선형 회귀를 진행한 그림이다. 3개의 곡선 중, 가운데 곡선은 초평면이고, 이 곡선과 ±e만큼 떨어진 곡선들이 형성하는 공간을 오류둔감 범위라 한다. 이 범위 안의 데이터는 손실을 0으로 처리하여 모델이 지나치게 세부적인 변동을 학습하지 않도록 한다. 반면, 이 범위를 벗어난 데이터는 초평면으로부터 떨어진 거리와 e의 차이가 손실로 부여되므로, 중요한 오차만 반영하는 특성을 지닌다.
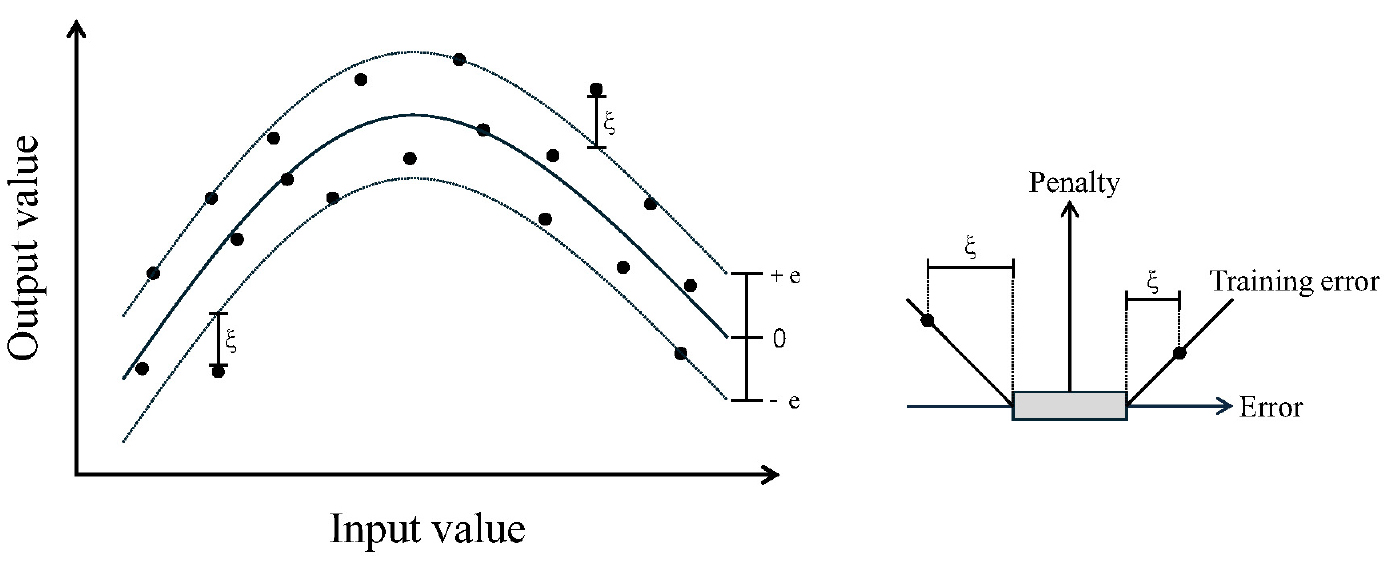
앞선 최적화 과정을 통해 얻어낸 해의 검증을 위해 메인문제(primal problem)을 쌍대문제(dual problem)로 변환한다. 쌍대문제는 라그랑지승수법을 적용하여 그 해를 도출하며, 이 경우 비선형 회귀문제도 효과적으로 해결할 수 있다. 비선형 회귀문제는 학습 데이터를 고차원의 특징 공간으로 사상(mapping)하여 비선형성을 선형적으로 다룰 수 있는 형태로 변환한 후, 이 공간에서 선형 회귀문제를 풀어 기존의 비선형 문제를 간접적으로 해결한다(Boser et al., 1992). 고차원 특징공간변환으로 인해 증가하는 계산 복잡도는 커널함수(Kernel function)를 통해 효율적으로 수행할 수 있다. 지반공학적 문제에 사용되는 커널함수에는 시그모이드 커널(Sigmoid Kernel), 다항식 커널(Polynomial Kernel), ERBF 커널(Exponential Radial Basis Function Kernel), RBF 커널(Radial Basis Function Kernel)이 있다. 시그모이드 커널은 신경망의 활성화 함수와 유사한 형태를 가지며, 비선형 데이터를 처리하는 데 사용된다. 다항식 커널은 입력 데이터의 다항식 관계 모델링에 사용되며, 선형적으로 분리되지 않는 데이터를 고차원 공간에서 선형적으로 분리할 수 있다. ERBF 커널은 두 데이터 사이의 거리에 대한 지수함수로 표현되며, 데이터의 유사성을 측정하는데 사용된다. RBF 커널은 두 데이터 사이의 거리에 대한 가우시안 함수로 표현되며, 많은 기계학습 알고리즘에서 사용된다(Boser et al., 1992; Vapnik, 1995).
3. 데이터수집
본 연구의 예측모델 개발에 사용된 유전율 데이터는 Shang(2002)에서 수집하였다. 유전율의 영향인자는 아스팔트포장의 시료길이(L), 상대밀도(), 함수비(w)와 골재의 곡률계수(), 아스팔트 함유율(BC)로 이는 학습모델의 독립변수이다. 아스팔트 유전율은 앞서 언급한 는 유전상수, 는 손실계수이며 이는 학습모델의 종속변수이다. 유전율 데이터는 총 106개이고, 이 중 모델의 개발과 예측에 각각 90개(85%)와 16개(15%)가 사용되었다. Table 1은 수집된 데이터의 통계치로 데이터의 최솟값, 최댓값, 평균, 표준편차이다.
Table 1.
Statistics of permittivity data used for model development
4. 예측모델 개발과 성능
아스팔트포장체의 유전상수와 손실계수를 예측하는 예측모델 개발을 위해 5개의 아스팔트 물성을 적용하여 학습하였다. 데이터학습에서 시그모이드, 다항식, ERBF, RBF의 커널함수를 사용하였다. 전체 90개 데이터 중 74개(70%)는 데이터학습에 적용하고 나머지 16개(15%)는 예측모델의 검증에 적용하였다. 즉, 학습데이터를 통해 얻는 예측모델의 검증데이터를 적용하여 도출된 유전율 결과값이 목표수준성능에 부합하지 못하면 데이터학습 단계로 돌아가 커널함수의 매개변수 조정을 통해 예측모델을 수정한다. 이러한 시행착오과정을 통해 최종적으로 검증데이터를 만족하는 예측모델을 도출한다.
한편, 예측모델의 예측 성능을 평가하는 지표로 결정계수(coefficient of determination, ), 평균절대비율오차(mean absolute percentage error, MAPE), 산포도지수(index of scatter, IOS)를 사용하였으며, 이들은 다음 식 (4),(5),(6)과 같이 표현된다.
여기서, n은 전체 데이터 수, 는 각각 i번째 관측값과 예측값이고, , 는 각각 관측값과 예측값의 산술평균이며, RMSE(root mean square error)는 평균제곱근오차이다. 값은 0과 1 사이의 값을 가지며, 1에 가까울수록 모델이 정확하게 예측하는 것이다. MAPE는 0~100% 사이의 값을 가지며, 0%에 가까울수록 모델의 예측 정확도가 높음을 의미한다. IOS의 값은 0이상으로 나타나며, 값이 작을수록 모델의 예측이 실제값에 가까워 성능이 높음을 의미한다. MAPE와 IOS는 실제값이 0에 가까울 때 예측값의 작은 오차에도 큰 영향을 받아 왜곡이 발생하는바, 본 연구에서는 > 0.8을 만족하도록 예측모델을 최적화하였다.
Table 2는 각 커널함수별 최적화된 예측모델의 매개변수의 수치를 나타낸다. 여기서, nsv는 예측모델에서 사용된 support vector의 개수이고, d는 다항식 커널에서 커널함수의 차수이며, γ는 시그모이드, ERBF, RBF 커널에서 사상 범위를 조절하는 값이다.
Table 2.
Optimal hyperparameter values for different Kernel functions
Table 3은 최적화된 예측모델의 유전상수에 대한 학습 결과를 나타낸다. 훈련과 검증과정을 통합한 학습과정에서 모든 커널의 는 0.74~0.94, MAPE는 0.01~0.03, IOS는 0.01~0.04의 범위를 보였다. 모든 커널에서 훈련과정의 가 검증과정보다 높은 결과를 보였지만, MAPE와 IOS의 결과를 보면 훈련과정에서의 오차가 오히려 더 크게 나타났다. 이는 는 예측값과 실제값 사이의 분산에 초점에 맞추는 반면, MAPE와 IOS는 예측값과 실제값의 상대적인 오차에 초점을 두는 지표이기 때문에 값과 반대되는 MAPE와 IOS의 경향이 나타날 수 있다. 커널의 성능을 비교하면 RBF 커널이 훈련과 검증과정에서 가장 좋은 결과를 보였다. ERBF 커널이 그 다음으로 좋은 결과를 보였으며, 시그모이드 커널이 가장 낮은 결과를 보였다. 이는 입력변수와 출력변수의 관계가 시그모이드 커널이 가정하는 비선형 형태와 부합하지 않아 모델이 오차를 충분히 줄이지 못한 것으로 기인한다.
Table 3.
Dielectric constant ε' of permittivity from training and validation
Table 4는 최적화된 예측모델의 손실계수에 대한 학습결과를 나타낸다. 학습과정에서 모든 커널의 는 0.92~0.96, MAPE는 0.05~0.10, IOS는 0.07~0.15의 범위를 보였다. 유전상수와 달리 MAPE와 IOS가 더 큰 이유는 예측 오차가 상대적으로 크게 반영되어 큰 영향을 받기 때문이다. 모든 커널에서 는 검증과정에 훈련과정보다 높거나 비슷한 성능을 보였고, MAPE와 IOS도 동일한 경향을 보였다. 각 커널의 성능을 비교하면 훈련과정에서는 RBF 커널이 우수하지만, 검증에서는 다항식 커널이 우수함을 보였다. 다만, 검증과정에서 RBF 커널과의 차이가 0.5%로 큰 성능차이는 보이지 않았다. 결과적으로 손실계수에서는 RBF와 다항식 커널이 우수한 성능을 보였으며, 유전상수와 동일하게 시그모이드 커널이 가장 낮은 성능을 보였다. 그러나, 시그모이드 커널의 도 0.92 이상을 보여 준수한 성능을 보였다. 이는 입력변수와 출력변수의 관계가 시그모이드가 가정하는 비선형 형태에 부합하거나, 데이터의 분포가 편향되지 않고 골고루 분포하여 모델이 안정적으로 학습했기 때문이다.
Table 4.
Loss factor ε'' of permittivity from training and validation
이상의 과정으로 만들어진 최적의 커널 예측모델을 사용하여 16개의 예측데이터로 유전율을 예측하였다. 최적의 커널은 유전상수와 손실계수의 학습과정에서 가 0.90을 넘는 ERBF와 RBF 커널을 사용하였다. Fig. 2와 Fig. 3은 예측모델을 통해 예측한 16개 데이터의 예측치와 실측치를 도시하였고, Table 5와 6에는 예측과정 결과에 대한 성능을 나타내었다. 유전상수 예측 결과 ERBF와 RBF 커널의 가 각각 0.953, 0.905으로 나타났으며, 이는 학습과정에서 비슷한 경향을 보여 예측모델이 잘 예측함을 볼 수 있다. 손실계수의 예측 결과 ERBF와 RBF 커널의 가 각각 0.872, 0.946으로 나타났다. ERBF 커널의 성능이 낮아진 이유는 데이터 사이의 거리에 직접적으로 반응하여 유사성을 측정하여 학습에는 유리하지만, 모델의 복잡도가 올라가 새로운 데이터에 대한 일반화 능력이 저하되기 때문이다. 다만, 많은 데이터를 수집하여 학습한다면 ERBF 커널이 데이터 사이의 다양한 관계를 학습하여 일반화 능력이 올라갈 수 있다.
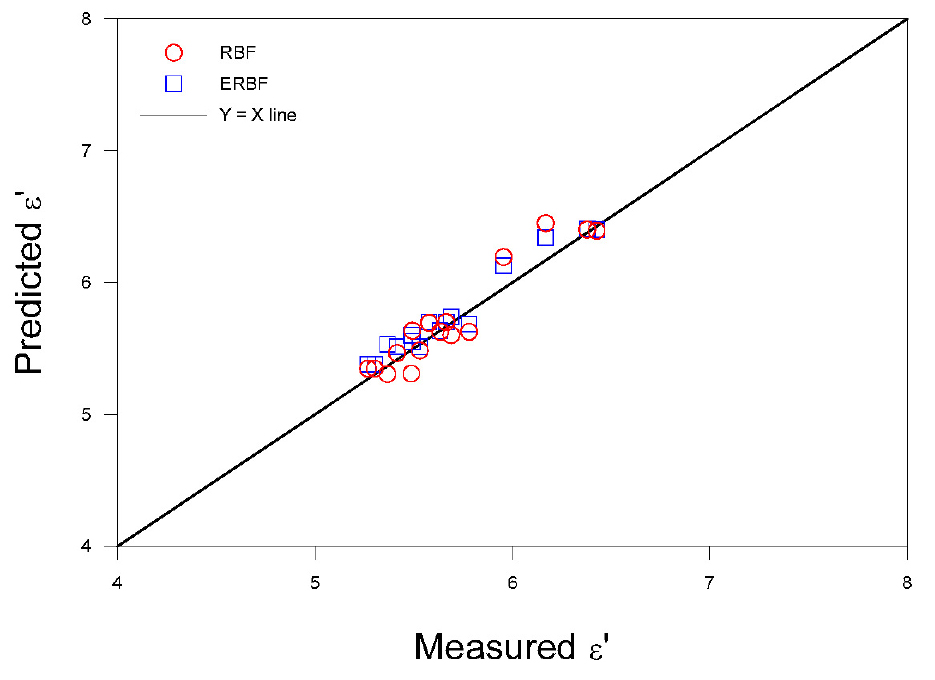
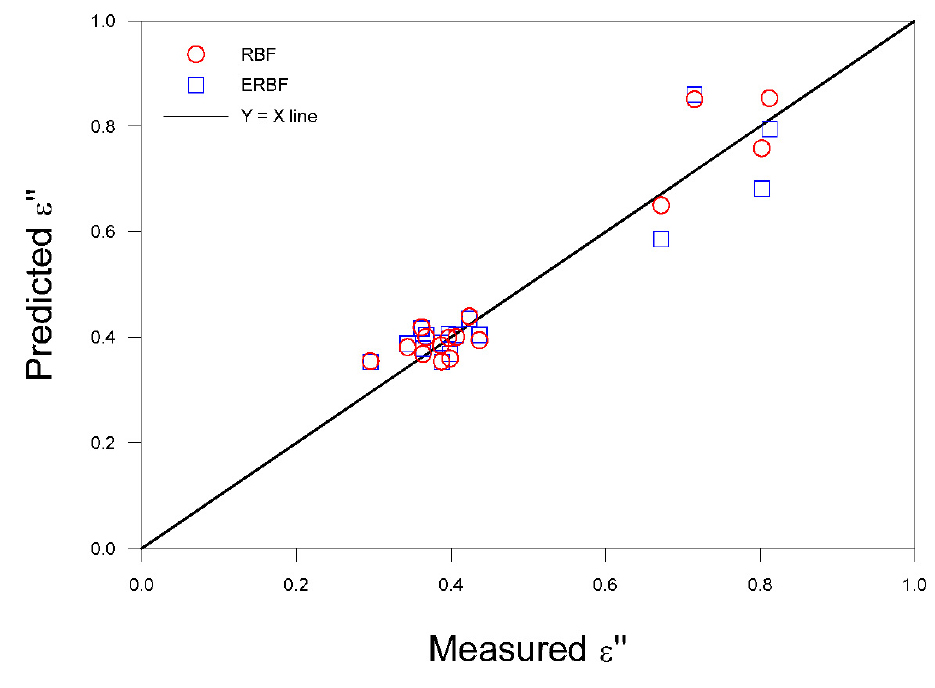
Table 5.
Dielectric constant ε' of permittivity from prediction
| ε' | ERBF | RBF |
| R2 | 0.953 | 0.905 |
| MAPE | 0.015 | 0.017 |
| IOS | 0.018 | 0.022 |
Table 6.
Loss factor ε'' of permittivity from prediction
| ε'' | ERBF | RBF |
| R2 | 0.872 | 0.946 |
| MAPE | 0.088 | 0.099 |
| IOS | 0.125 | 0.144 |
본 연구에서 수행된 예측 성능을 기존 문헌과의 비교를 위해 Shang(2002)의 값과 비교하였다. 기존 문헌에서는 다중선형회귀법을 사용하여 유전율을 예측 및 분석하였으며, 유전상수와 손실계수에서의 값은 각각 0.790, 0.885의 값을 보였다. 본 연구에서 사용한 ERBF와 RBF 커널 기반 예측모델의 성능과 비교하면 ERBF 커널의 경우 손실계수에서 기존보다는 낮은 성능을 보였지만, RBF 커널의 경우 유전상수와 손실계수에서는 모두 높은 성능을 보였다. 결과적으로 본 연구에서 사용한 SVR 예측모델이 기존보다 높은 성능을 보여 아스팔트포장의 유전율 예측에 있어 좋은 방법이라 할 수 있다.
5. 결 론
본 연구로부터 얻은 결론은 다음과 같다.
1) 본 연구에서 사용한 SVR 예측모델은 학습단계에서 높은 를 보여, 아스팔트포장과 유전율 간의 관계를 효과적으로 파악됨을 확인하였다.
2) ERBF, RBF 커널을 적용한 SVR 예측모델은 유전상수와 손실계수를 예측하는데 높은 를 보였으며, 이는 입력된 아스팔트포장 정보만으로도 유전율을 신뢰성 있게 추정할 수 있음을 의미한다.
3) Shang(2002)의 연구 결과와 비교했을 때, 본 연구에서 사용한 모델이 더 높은 예측 성능을 보였다. 이는 아스팔트포장의 유전율 해석에 있어 본 연구의 모델이 더 신뢰성 있는 결과를 제공할 수 있음을 보여준다.
4) 본 연구에서 사용한 모델을 활용하면, 아스팔트포장 데이터를 입력값으로 주어졌을 때 아스팔트포장의 유전율을 단시간에 정확하게 평가할 수 있다.
이는 GPR 활용 시 데이터 해석 과정의 효율성을 높이고, 아스팔트포장의 평가 및 유지관리에 기여할 수 있을 것으로 기대된다. 또한, 향후 예측모델의 성능을 개선하기 위해서는 아스팔트포장의 유전율을 측정할 때 해당 시점의 온도 데이터를 함께 수집하여 모델에 반영하는 것이 필수적이다. 이러한 접근을 통해 온도 변화와 아스팔트포장과 유전율 간의 상관관계를 더욱 정확하게 파악할 수 있으며, 이는 모델의 예측 정확도 향상으로 이어질 것으로 판단된다.
