

1. 서 론
2. 자료 수집 및 분석 방법
2.1 데이터 수집
2.2 분석 방법
3. 변수의 설정 및 사건발생 확률 산정
3.1 독립변수 및 종속변수 설정
3.2 SMOTE
3.3 하이퍼파라미터
3.4 특정 조건에서의 중상이상사고 확률 산정
4. 결과 분석
4.1 서울특별시 음주사고취약지역 선정
4.2 음주사고취약지역 상위 사고영향 변수중요도
5. 결 론
1. 서 론
자동차는 현대 사회에서 필수적인 교통수단으로 자리 잡으며 우리의 일상과 함께하고 있다. 2023년 기준 국내 자동차 등록대수는 총 25,949,201대로 전년 대비 1.7% 증가하였으며, 연도별 자동차 등록대수의 추이는 계속해서 증가하는 추세이다. 운전면허소지자의 경우에도 2022년 기준 34,133,763명으로 전체 인구 대비 약 65% 가량이 운전면허를 소지하고 있으며, 이 수치 또한 매년 증가하는 추세이다(KOSIS, 2023a, 2023b). 이처럼 자동차와 운전면허 소지자의 증가는 교통수단 이용의 편리함과 개인의 이동성을 크게 향상시키는 긍정적인 영향을 미치지만 동시에 교통량의 증가로 인한 교통사고 발생률의 상승과 같은 부정적인 사회적 문제도 야기하고 있다. 특히, 음주운전은 교통사고 발생 원인 중 하나로 여전히 심각한 문제로 남아 있다. 음주운전으로 인한 교통사고는 2010년 28,641건에서 2023년 13,042건(KRTA, 2024)으로 현저히 줄어들었지만 음주운전으로 인한 피해는 여전히 막대하다는 점에서 그 빈도가 여전히 절대적으로 많다고 여겨진다(Kyoung, 2024).
교통사고는 인적요인, 차량요인, 도로환경요인 등 다양한 요인들이 발생하여 야기되며, 단 한 가지의 문제로 발생되는 것이 아닌 다양한 요인들이 복합적으로 작용하여 발생한다. 교통사고는 일반적으로 93-94% 이상이 운전자 원인으로 보고되고 있어 운전자의 운전행태가 가장 중요한 요인으로 작용한다(Ogden, 1996). 특히, 이러한 인적요인은 교통사고에 있어 주요 원인으로 작용하기 때문에 이로 인한 음주운전사고는 경각심을 가지고 해결해야 할 문제 중 하나이다.
최근 교통사고를 예측하는데 있어 머신러닝(Machine Learning)이나 딥러닝(Deep Learning) 등 AI기법을 적용한 연구가 늘어나고 있다. 교통사고 연구에서 전통적 통계기법은 상대적으로 넓은 지역을 포괄하는 지역 수준의 평균 데이터를 기반으로 사고 요인을 분석하여 교통사고 지점과의 직접적 연관성을 파악하기 어려운 한계가 있는 반면, AI 기법은 이러한 문제를 효과적으로 해결할 수 있는 장점을 가진다(Ibrahim et al., 2021). 연구사례를 보면, Yoon et al.(2016)은 고속도로 공사구간에서의 사고 심각도 영향 요인을 분석하고, 이를 기반으로 안전성 증진 방안을 제안하였다. 순서형 프로빗 모형을 적용한 결과, 속도, 차로 폐쇄에 따른 용량 감소, 사고 위치, 공사 작업 유형 등이 주요 요인으로 나타났다. Seo and Lee(2016)은 보행자 교통사고와 관련된 물리적 환경 요인을 분석하였다. 서울시 TAAS 데이터를 활용하여 교통량, 도로 설계, 주변 환경이 보행자 사고 심각도에 미치는 영향을 파악하였다. Kim and Lee(2019)은 음주사고 데이터와 공간 분석을 결합하여 사고발생위험지역을 예측하는 데 중점을 두었다. 빅데이터 분석을 통해 특정 시간대와 공간에서 음주사고가 집중적으로 발생하는 경향을 발견하였으며, 이를 기반으로 사고발생위험지역을 지도화하여 예방 정책 수립의 기초 자료로 활용될 수 있음을 제시하였다. Kim et al.(2021)은 4개의 기계학습 알고리즘을 활용하여 고령운전자에 의한 차대사람 사고심각도 예측 모형을 개발하고 각 결과를 비교하였으며, 중요 변수들을 이용하여 교차분석을 수행하고 그 결과를 제시하였다. Jun et al.(2021)은 딥러닝 기술을 활용하여 보행자 교통사고다발지역을 예측하였다. 수도권 데이터를 기반으로 교통 약자(노인, 어린이)의 사고위험지역을 모델링하였으며, 딥러닝 모델이 기존 통계적 분석 기법보다 높은 예측 정확도를 제공함을 보여주었다. Lee et al.(2024)은 RandomForest를 활용하여 고속도로 노선에서 발생한 교통사고 자료를 활용하여 사고 심각도 분석 및 사고 심각도에 미치는 영향요인을 도출하였으며, 고속도로 사고 데이터를 심층적으로 분석함으로써 사고의 심각도를 효과적으로 예측할 수 있음을 보여주었다.
본 연구는 음주운전과 관련된 도로교통사고의 심각성, 특히 중상 및 사망사고로 이어질 가능성에 영향을 미치는 요인을 분석하고 이를 기반으로 RandomForest 머신러닝 알고리즘을 활용하여 서울특별시 음주사고취약지역을 선별하고자 한다. 또한, 분석 결과를 바탕으로 취약지역 내 교통사고 예방과 피해 저감을 위하여 사고의 주요 변수를 산정하여 이에 대한 상세분석을 실시하고자 한다.
2. 자료 수집 및 분석 방법
2.1 데이터 수집
본 연구에서는 서울특별시에서 발생한 음주교통사고를 분석하기 위해 한국도로교통공단 교통사고분석시스템(TAAS)에서 제공하는 2018부터 2023년까지 6개년의 음주교통사고 데이터를 수집하여 활용하였다. 수집된 데이터에 대한 내용 및 구성을 Table 1에 나타내었다.
대상 데이터 분석 결과 전체 데이터 개수는 13,718건으로 나타났으며, 그 중 부상신고사고는 591건, 경상사고는 9,834건, 중상사고는 3,190건, 사망사고는 103건으로 나타났다. 이에 중상이상사고는 전체 데이터 중 24%를 차지하며 사고의 심각도를 줄이기 위한 예방 대책의 필요성을 시사한다.
Table 1.
Data configuration
2.2 분석 방법
머신러닝(Machine-Learning)은 데이터로부터 학습하여 예측 모델을 생성하거나 의사결정을 자동화하는 기술로, 인공지능(AI)의 한 분야로 자리 잡고 있다. 전통적인 프로그래밍 방식과 달리, 머신러닝은 명시적인 규칙 기반의 코딩이 아닌 데이터를 활용해 스스로 패턴을 학습하는 알고리즘 개발에 초점을 맞춘다. 머신러닝은 대규모 데이터에서 유의미한 패턴을 자동으로 발견함으로써 분석 효율성을 극대화하며, 복잡한 문제에 대한 예측 정확도를 향상시키고, 기존 규칙 기반 시스템보다 적응성이 뛰어나다.
RandomForest는 앙상블 학습(Ensemble Learning) 기법에 기반한 머신러닝 알고리즘으로, 다수의 결정 트리(Decision Tree)를 결합하여 예측 성능을 향상시키는 데 중점을 둔다. 이 알고리즘은 분류(Classification) 및 회귀(Regression) 문제 모두에 적용 가능하며, 특히 데이터의 과적합을 효과적으로 방지하면서 높은 예측 정확도를 제공한다(Fig. 1).
RandomForest의 작동 원리는 데이터로부터 무작위로 샘플을 추출하여 여러 개의 결정 트리를 생성한 뒤, 예측 시 다수결(분류) 또는 평균화(회귀)를 통해 최종 결과를 산출하는 방식이다. 이러한 과정은 각각의 트리가 약한 학습기이지만, 다수의 트리를 결합함으로써 강한 학습기를 형성할 수 있도록 한다. 특히, 무작위성 도입으로 인해 트리 간 상관성을 줄이고 모델의 일반화 성능을 향상시키는 데 기여한다. RandomForest는 높은 예측 정확도와 효율적인 계산 성능, 그리고 입력 변수의 중요도를 평가할 수 있는 기능 등으로 인해 다양한 분야에서 널리 활용되고 있으며, 최근 교통사고다발구간의 예측, 사고 심각도 평가 등 교통 분야에서도 연구가 활발히 이루어지고 있다.
3. 변수의 설정 및 사건발생 확률 산정
3.1 독립변수 및 종속변수 설정
중상이상의사고를 대상으로 분석을 진행하기 위해 중상자 및 사망자의 발생 여부를 종속 변수로 설정하였다. 독립변수의 설정에 있어 데이터 누수를 유발할 수 있는 변수를 제거하여 데이터의 Overfitting의 방지하였다. 제거 변수로는 불필요한 데이터인 사고번호와 종속변수의 설정으로 인해 불필요하게 된 사망자수, 중상자수, 사고내용, 가해운전자 상해정도, 피해운전자 상해정도를 설정하였다. 이를 제외하여 선정된 독립변수를 Table 2에 나타내었다.
Table 2.
Independent variable
3.2 SMOTE
대상 데이터의 클래스 불균형 문제를 해결하기 위하여 SMOTE 오버샘플링 기법을 사용하였다. 데이터의 클래스 불균형은 머신러닝 모델의 학습에 부정적인 영향을 미칠 수 있다. 이에 SMOTE는 소수 클래스 데이터의 새로운 샘플을 생성하여 데이터 균형을 맞추는 데 활용된다. 생성된 새로운 샘플은 기존 데이터와 함께 모델 학습에 사용되며, 기존 소수 클래스의 데이터 분포를 유지하면서 데이터를 보강하는 방식으로 모델의 성능을 향상시킬 수 있다. Table 3에 SMOTE 기법을 적용한 후의 RandomForest 모델의 성능을 나타내었다.
Table 3에 나타난 바와 같이 모델 성능은 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-score로 평가하였다. 정확도란 판별한 전체 샘플 중 True Positive(TP)와 True Negative(TN)의 비율을 나타내며 전체 예측 중에서 모델이 정확하게 맞춘 비율을 나타낸다. 정밀도는 모델이 Positive라고 예측한 값 중 실제로 Positive인 비율을 나타내며, 재현율은 실제로 Positive인 값 중에서 모델이 Positive로 잘 예측한 비율을 나타낸다. 재현율이 높을수록 실제 Positive를 놓치지 않고 잘 찾아낼 수 있다. F1-score는 정밀도와 재현율의 조화 평균으로서 이들 간의 균형을 평가할 때 사용되며 불균형 데이터에서 성능을 평가하기에 용이한 특징이 있다.
Table 3.
RandomForest performance (SMOTE)
| Type | precision | recall | F1-score | accuracy |
| macro avg | 0.73 | 0.74 | 0.73 | 0.76 |
| weighted avg | 0.76 | 0.73 | 0.75 |
3.3 하이퍼파라미터
모델 성능을 추가적으로 개선하기 위해 GridSearchCV를 이용하여 하이퍼파라미터 튜닝을 수행하였으며 이때, 튜닝된 하이퍼파라미터는 n_estimators, max_depth, min_samples_split, min_samples_leaf, class_weight이다. F1-score을 기준으로 교차 검증을 수행한 결과, 최적의 하이퍼파라미터를 정리하여 나타내면 Table 4와 같다.
Table 4에서 n_estimators는 RandomForest에서 생성할 트리의 개수를 의미하며, 본 연구에서는 100으로 설정하였다. 트리의 개수를 늘리면 모델의 성능이 안정화되고 예측 결과의 분산이 감소하는 효과가 있다. 다만 트리가 많아질수록 학습 시간과 계산 비용이 증가하기 때문에 최적값으로 설정된 100은 성능 개선 효과와 계산 비용 간의 균형을 고려한 결과이다. max_depth는 각 트리의 최대 깊이를 제한하는 하이퍼파라미터로, 본 연구에서는 10으로 설정하였다. 트리의 깊이가 너무 깊으면 데이터의 세부적인 특성까지 학습하게 되어 과적합(overfitting)이 발생할 수 있다. 반대로, 트리의 깊이를 적절히 제한하면 불필요한 세부사항을 학습하지 않아 과적합을 방지할 수 있다. max_depth=10은 트리의 복잡성을 제한하면서도 충분히 유의미한 예측 성능을 도출할 수 있도록 설정된 값이다. min_samples_split은 노드를 분할하기 위해 필요한 최소 샘플 수를 의미하며, 본 연구에서는 5로 설정되었다. 노드 분할 시 최소 샘플 수가 너무 작으면 불필요한 분할이 지나치게 발생하여 과적합 가능성이 증가한다. min_samples_split=5는 노드에 최소한 5개의 샘플이 있어야 분할이 수행되도록 하여 데이터가 지나치게 세분화되는 것을 방지한다.
Table 4.
Optimal hyperparameters
| Hyperparameter | |
| n_estimators | 100 |
| max_depth | 10 |
| class_weight | None |
| min_samples_split | 5 |
| min_samples_leaf | 1 |
| Optimal Hyperparameters ROC-AUC Score | |
| 0.9204 | |
min_samples_leaf는 리프 노드에 있어야 하는 최소 샘플 수를 지정하는 하이퍼파라미터로, 본 연구에서는 1로 설정되었다. 리프 노드에 하나의 샘플만 포함되는 것을 허용하여 모델이 다양한 데이터 구조를 학습할 수 있도록 하였다. 데이터가 충분히 크고 다양하다면 min_samples_leaf=1로 설정해도 모델이 안정적으로 작동할 수 있으며, 현재 데이터에서도 이 값이 적합한 것으로 나타났다. class_weight는 클래스 불균형을 처리하기 위해 각 클래스에 가중치를 부여하는 설정으로, 앞서 SMOTE를 적용하여 소수 클래스에 대한 데이터 균형을 이룬 상태이므로 None으로 설정하였다. 이는 데이터의 클래스 비율을 그대로 사용한 것으로, 현재 데이터에서는 클래스 불균형이 성능에 크게 영향을 미치지 않는 것으로 판단되었기 때문이다. 그러나 클래스 불균형이 심할 경우, class_weight=‘balanced’를 사용하여 각 클래스 빈도에 따라 가중치를 자동으로 조정할 수 있다. 마지막으로 튜닝된 하이퍼파라미터를 기반으로 학습된 모델의 성능을 Table 5에 나타내었다.
Table 5의 결과를 Table 3과 비교해 보면, 전반적으로 모든 부분이 향상된 점을 알 수 있다.
Table 5.
RandomForest performance (Hyperparameter)
| Type | precision | recall | F1-score | accuracy |
| macro avg | 0.79 | 0.74 | 0.76 | 0.78 |
| weighted avg | 0.81 | 0.73 | 0.78 |
3.4 특정 조건에서의 중상이상사고 확률 산정
RandomForest 모델의 predict_proba를 사용하여 입력된 특정 변수 조건에 따라 중상이상사고 발생 확률을 추정할 수 있다. 이 방법은 머신러닝 기반의 확률적 예측을 통해, 특정 조건에서의 사고 발생 가능성을 정량적으로 평가하는 데 사용된다. 이는 단순히 사고 유형을 구분하는 데 그치지 않고, 다양한 독립 변수 간의 상호작용을 반영하여 보다 현실적이고 세부적인 사고 발생 확률을 예측할 수 있다는 점에서 의의를 가진다. 예를 들어, 특정 지역, 사고 발생 요일, 운전자의 연령, 도로 형태 등과 같은 조건을 입력 변수로 활용할 경우 모델은 해당 조건에서의 중상이상사고 발생 가능성을 계산해준다. 이를 통해 우리는 특정 변수 조합에서 중상이상사고가 발생할 위험도를 객관적으로 비교할 수 있다. 이러한 분석은 고위험군을 선별하거나 사고 예방 정책을 수립하는 데 있어 유용한 지표로 활용될 수 있다.
Table 6은 몇 가지 대표적인 조건에 대해 predict_proba를 적용한 결과를 정리한 것이다. 이를 통해 특정 변수 조건에 따라 중상이상사고 확률이 어떻게 변화하는지를 파악할 수 있다.
Table 6.
Estimation of severe accident probability under variable conditions
4. 결과 분석
4.1 서울특별시 음주사고취약지역 선정
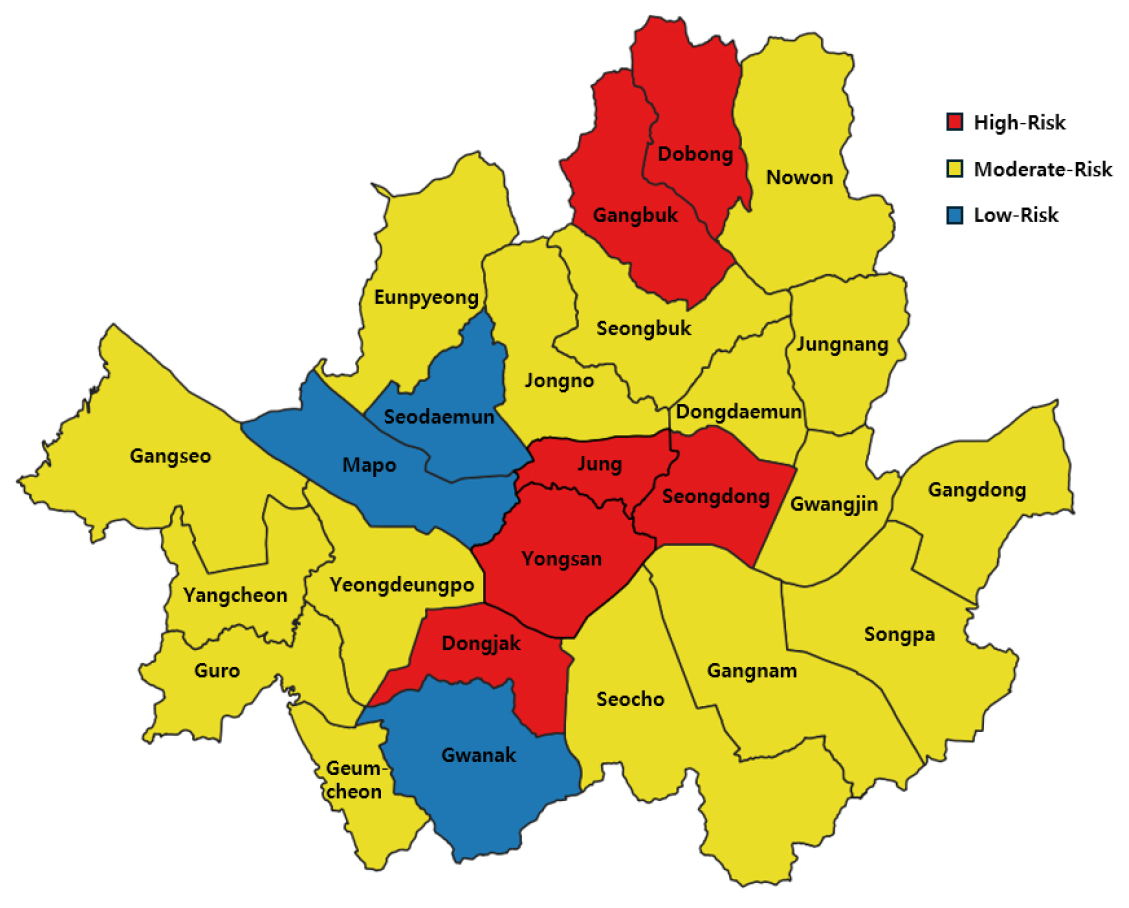
최적 하이퍼파라미터를 적용하여 대상 음주사고 데이터 서울특별시 내에 있는 각 자치구별로 구분하여 분석하였으며, 각 자치구별 중상이상사고 발생의 평균 확률과 모델의 ROC-AUC 점수를 산출하여 Table 7에 나타내었다. 평균 확률은 각 자치구에서 테스트 데이터에 대해 예측된 중상이상사고 확률의 평균값으로 계산되었으며, ROC-AUC 점수는 자치구별 데이터 크기 및 특성에 따라 일부 차이를 보였으며, 데이터 크기가 충분하지 않은 경우, 그 성능이 제한됨을 확인하였다. 또한, 서울특별시 내 자치구별 중상이상사고발생평균확률의 평균값과 표준편차를 산정하여 평균+1표준편차 이상의 확률이 산정된 자치구에 대해서 High-Risk, 평균-1표준편차 이상의 확률이 산정된 자치구에 대해서는 Low-Risk, 그외 평균과 가까운 확률이 산정된 자치구에 대해서는 Moderate-Risk으로 지칭하였다. 이상의 연구결과를 정리하여 나타내면 Table 7과 같으며 이를 수치지도 상에 표시하여 나타내면 Fig. 2와 같다.
Table 7.
Prediction of severe accident probability in Seoul
4.2 음주사고취약지역 상위 사고영향 변수중요도
사고영향 변수중요도는 Table 2에 나타낸 변수들 사이의 상대적인 중요도를 평가하는 것으로 대책마련의 우선순위를 정하는 매우 효과적인 지표이다. 본 연구에서는 Table 7에서 High-Risk 지역으로 선정된 강북구, 도봉구, 동작구, 성동구, 용산구, 중구를 대상으로 주요 변수를 종합하여 High-Risk 지역 내에서의 변수 중요도 비중을 산정하여 그 순위를 Table 8에 나타내었다.
High-Risk 지역에 대한 분석결과, 가해운전자 연령대는 20대와 30대, 사고형태는 차와 사람, 그리고 차대차 간의 사고가 대부분이었으며, 요일은 주말로 특히, 금요일 오후 10시부터 토요일 오전 2시 사이에 가장 많은 음주운전 사고가 발생한 것으로 나타났다.
5. 결 론
본 연구는 음주운전으로 인한 막대한 사회적 손실과 인명피해를 경감하고자 2018년부터 2023년까지 6개년의 서울특별시의 음주사고 데이터를 바탕으로 RandomForest 알고리즘 기반 머신러닝을 활용하여 음주사고취약지역을 예측한 것이다.
1) 클래스 불균형 문제가 존재하여 이를 해결하기 위해 SMOTE(Synthetic Minority Oversampling Technique)기법을 적용하여 소수 클래스인 중상이상사고 데이터를 보강함으로써 모델 학습의 공정성과 예측 성능을 개선하였다. 또한, RandomForest 알고리즘의 예측 성능을 개선하기 위해 하이퍼파라미터 최적화를 수행하여 모델의 전반적인 성능을 보완하였다.
2) 서울특별시 자치구별 음주사고 데이터를 기반으로 강북구, 도봉구, 중구, 용산구, 성동구, 동작구를 중상이상사고(중상사고 및 사망사고) 발생 가능성이 높은 High-Risk 지역으로, 서대문구, 마포구, 관악구를 Low-Risk 지역으로 분류하였다. 분류된 데이터를 기반으로 자치구별 사고 위험도를 시각적으로 나타내는 Risk Map을 작성하였다.
3) High-Risk 지역의 중상이상사고 발생 확률과 연관된 변수 중요도를 산출한 결과, 사고에 주요 영향을 미치는 변수로 가해운전자 및 피해운전자의 연령대, 법규위반(안전운전불이행), 사고가 자주 발생하는 주말(금요일 및 토요일), 그리고 사고유형으로는 차대사람 사고와 차대차 추돌 사고가 도출되었다. 이러한 변수들은 음주운전 사고의 주요 요인으로서 효과적인 사고 예방 정책 수립의 기초 자료로 활용될 수 있다.
4) 추후 음주사고와 중상이상사고 간의 연관성을 정량적으로 분석하여 특정 변수가 음주운전 사고에 미치는 영향을 파악하는 연구가 필요하다고 생각된다. 또한, High-Risk 지역에서 도출된 주요 변수를 기반으로 사고 예방 대책을 수립 및 예방 대책의 영향력을 분석하고 개선 방안을 마련하기 위한 연구가 필요할 것으로 사료된다.
5) 본 연구는 서울특별시의 6개년의 데이터를 대상으로 한 것으로 데이터의 폭을 넓히고 다양한 지역의 데이터를 포함한 분석과 함께 사고의 심각도를 고려한 추가적인 가중치의 적용이 이루어진다면 전국의 음주운전 사고의 원인분석과 대책마련에 이 연구가 크게 도움을 줄 수 있을 것으로 판단된다.
