

1. 개 요
2. 관련 연구
3. 방법론
3.1 제안된 방법론 요약
3.2 노면영상 취득
3.3 이미지 전처리
3.4 딥 전이 학습을 이용한 의미론적 이미지 분할
4. 현장시험 실증을 통한 성능평가
4.1 Dataset
4.2 모델훈련
4.3 Evaluation metrics
4.4 결과분석
5. 결론 및 논의
1. 개 요
포장유지관리에 있어 일상적인 포장노면 점검은 차량을 이용해 주행 하며, 또는 도보를 통해 걸으며 사람의 육안확인에 의존한 방식으로 이뤄져왔는데, 이는 시간과 비용 소모적인 것은 물론이며 점검자를 사고 위험에 노출시키는 방식이다. 이를 해결하기 위한 포장의 노면 상태 점검의 자동화를 위한 많은 노력이 이루어져 왔으며, 특히 점검 장비에 대한 비용적 제약을 극복하기 위해 디지털 카메라(Quintana et al., 2016; Mei and Gül, 2020; Park et al., 2021), 휴대폰카메라(Alam et al., 2020; Patra et al., 2021), 블랙박스(Jo and Ryu, 2015; Meocci et al., 2021) 등을 차량의 내부 또는 외부에 설치하여 데이터를 수집하는 방식들이 제안되었다. 이러한 장비들은 파손의 깊이 정보가 없는 2차원 이미지 데이터만 수집이 가능 하지만, 쉬운 설치와 경제성 측면에서 장점이 있다. 3차원 깊이 정보 수집을 위해 Kang and Choi(2017)은 2D LiDAR, Chang et al.(2005)과 Wu et al.(2019)은 3D Laser을 이용한 방법을 제안하였으나, 지역의 포장유지관리 현장에서 일상적으로 상시 이루어져야 하는 점검에 활용하기에는 가용성이 부족하다. Pan et al.(2017), Inzerillo et al.(2018), Silva et al.(2020), Zhu et al.(2022)은 차량의 주행 중 점검에 따른 한계를 극복하기 UAV 이용한 포장파손 자동탐지 시스템을 제안하였다. 실무적인 측면에서는 노면을 수직으로 촬영하는 2D, 3D 스캐닝 장비는 상대적으로 고가이기 때문에, 주로 휴대폰카메라, 비디오카메라 등의 저가의 실용적 장비를 활용한다. 이들로부터 수집되는 GPS 좌표정보, 촬영 이미지, 텍스트 파일 등의 데이터는 저용량으로 무선 통신망을 통해 실시간 전송이 가능하여 시스템의 구축 운영도 용이하다(Jo and Ryu, 2015; Park et al., 2021). 그러나 주행 중 촬영되는 동영상에는 동일 파손이 여러 개의 정지 이미지(프레임)에 존재하게 되어 파손의 수량을 세거나 면적을 확인하는 등과 같은 정량화 활용에는 제약이 있다. Radopoulou and Brilakis(2014)은 이에 대한 해결책으로 트레킹 기법을 이용한 중복 처리를 제안하였지만 전역적인 포장 상태를 조망할 수 있는 노면 이미지의 취득은 여전히 불가능하다. 수직으로 촬영하는 스캔 방식의 경우에는 노면이 연결된 파노라마 이미지로 포장 면의 전역적인 관찰이 가능해 동일 파손이 중복하여 탐지되지 않는 장점이 있다. 또한 왜곡이 적어 보다 나은 탐지 성능과 정량화에 유리하다. 반면 상대적으로 화각이 좁아 데이터 취득의 효율이 낮고, 노면 부분만을 촬영하므로, 주변을 인식할 수 있는 환경에 대한 정보가 없다는 단점이 있다.
영상데이터를 이용해 포장의 파손 탐지 분석을 자동화 하는 연구도 활발히 이뤄지고 있는데, 탐지 대상에 따라 단일 유형 탐지, 다수 유형 탐지 분류로 구분되며, 분석 수준에 따라 이미지 내에서 파손의 존재 유무를 분류하는 것, 파손의 유형과 위치를 알아내 것, 포장상태를 평가하는 지표를 생성하는 것 등으로 구분할 수 있다. 또한 실시간, 준실시간 분석 그리고 오프라인 분석으로 구분된다(Sarsam, 2016; Coenen and Golroo, 2017; Zakeri et al., 2017; Ragnoli, 2018). 컴퓨터 비전 기반 포장 손상 탐지 분석 연구의 초기에는 강도-임계값(intensity-thresholding), 경계 탐지(edge detection)와 같은 전통적인 이미지 처리기법을 이용한 것과 SVM(Support Vector Machine) 등과 같은 일반 기계학습에 기반한 방법론이 주로 적용되었다. 최근에는 합성곱 신경망 딥러닝의 급격한 발전에 따라 비전 기반의 파손탐지의 주된 접근법으로 응용되고 있다(Gopalakrishnan, 2018; Peraka and Biligiri, 2020).
이처럼 많은 연구에서 자동화된 포장 점검 시스템과 분석방법론 등을 제안하고, 실무적으로도 적용되고 있지만, 파손부에 대한 재파손 발생 또는 보수 여부 등에 대한 파악을 위해 수시로 점검하고 관리하여야 하는 포장 패치의 자동 탐지 분석에 대한 연구는 매우 제한적이다. 포장의 파손부위를 절삭하여 임시적으로 아스팔트 또는 콘크리트 포장 재료로 메꿔놓은 부분인 포장 패치는 상대적으로 넓은 면적을 차지해 전방 카메라 영상 한 프레임 범위를 넘어가는 경우 전체 패치 영역의 탐지가 어렵다. 따라서 지역적인 시야 보다는 전역적인 시야로 포장 노면의 특이사항들에 대해 자동으로 탐지하고 취득하는 자동화 방법이 필요하다.
본 연구에서는 지역 현장의 도로관리기관이 포장상태의 일정점검 중 필수적으로 점검해야 하는 포장 패치에 대하여 저비용의 비전 시스템과 딥러닝을 활용한 이미지 분할 방식의 자동 탐지 방법을 제안하다. 차량의 주행 전방을 촬영한 비디오 영상에 대하여 탐지 성능을 높이고 정량화 분석에 유리하도록 정사영으로 변환한 후 도로면의 관심영역을 잘라낸다. 그리고 포장파손에 대한 전역적인 뷰를 얻을 수 있도록 주행 속도에 기반하여 선택된 프레임들을 스티칭하여 파노라마 이미지를 생성한다. 그리고 보수부의 정량화를 위한 기반을 제공하는 픽셀 단위의 분류를 위해 이미지 분할 네트워크 U-net을 적용하여 포장 패치부를 자동으로 탐지하는 방법을 제안한다. 최고의 성능을 갖는 모델 구축을 위해 인코더에 최신의 합성곱 심층신경망 특징 추출기들의 전이 학습을 수행하였다.
이후 부분에는, 2장에서는 포장의 상태를 자동을 탐지 시스템과 딥러닝 기반의 자동 분석 방법론의 관련연구를 고찰하며, 3장에서는 차량에 설치된 저비용의 카메라로 부터 취득된 노면영상을 처리하는 이미지 처리 기법과 U-net을 활용한 패치 자동탐지 방법을 제시한다. 4장에서는 실제 고속도로에서 촬영한 노면 영상을 이용하여 얻어진 파노라마 이미지를 이용해 최적의 모델을 개발하기 위한 실험과 훈련에 사용되지 않은 다른 구간의 영상을 이용하여 제안된 탐지된 포장 패치 탐지 모델의 성능을 평가하고, 5장에서는 본 연구의 결론과 향후 연구방향에 대한 논의로 마무리한다.
2. 관련 연구
인력에 의한 주관성의 개입을 예방하고, 인력 소모적인 기존의 포장상태 탐지 분석을 자동화하기 위해 비용 효과적인 데이터 수집과 자동화된 분석 방법론에 대한 많은 연구가 있어 왔다. Alam et al.(2020)은 휴대폰 기반의 도로 상황 탐지 시스템을 제안하였는데 이상치들에 대한 후보 신호를 인식하는 단계와 서버에서 의사결정 트리를 이용해 분류하는 2단계로 작동한다. Patra et al.(2021) 역시 휴대폰 기반의 도시 전역의 포트홀을 실시간으로 탐지하고, 공간상에 매핑하는 종단간 시스템을 제시하였다. Jo and Ryu(2015)는 블랙박스 카메라의 임베디드 컴퓨팅 환경에서 작동하는 포트홀 탐지 시스템을 제안하였다. 임베디드 보드에 설치된 이미지 처리기법을 이용한 탐지 알고리즘을 통해 실시간으로 포트홀을 탐지하고, 위치와 크기 정보를 서버로 전송한다. Zhu et al.(2022)는 고해상도 카메라가 탑재된 UAV를 이용해 노면 이미지를 취득하고 딥러닝 객체 탐지 모델들을 이용해서 균열 4종, 패치, 포트홀의 파손유형에 대한 탐지성능을 비교 평가하였다.
Maeda et al.(2018)은 스마트폰을 사용한 SSD Inception V2와 SSD MobileNet의 포장파손 탐지 정확도와 런타임 속도를 비교하였다. Wu et al.(2019)는 모바일 장비에서 촬영한 이미지에 YOLO, CenterNet, EfficentDet과 같은 객체 탐지 모델의 버전별, 백본별로 성능을 리소스와 정확도를 평가하였다. Lei et al.(2020)은 구글 스트리트뷰 이미지를 수집하여 8종의 파손유형에 대한 학습데이터 셋을 만들고, 사전 학습된 YOLOv3를 사용하여 실시간으로 탐지하는 방법론을 제안하였다. Ukhwah(2019)와 Dharneeshkar(2020)는 포트홀 탐지에 YOLO 모델을 적용하였다. Cao et al.(2020)는 다종의 대시캠 이미지 소스에 물체 감지 분야의 좋은 성능을 나타낸 DCNN 모델들을 적용하는 방법을 제안하였다. Cao et al.(2020), Lei et al.(2020)은 MMS 차량의 카메라로부터 얻어진 정사 프레임이미지에서 사전 학습된 딥러닝 기반 포장 파손 탐지 모델을 구축하였다. Wu et al.(2019)은 2차원 이미지에서 DeepLabv3+ 의미론적 분할 모델을 통해 후보 포트홀을 추출하고, 레이저 스캐닝 기반의 포인트 클라우드에서 이미지와 포인트 클라우드 관계에 기반하여 3차원 포트홀을 추출하는 결합된 알고리즘을 제안하였다. Chen et al.(2020)은 SegNet을 참조하여 완전한 합성곱 신경망 기반의 콘크리트 포장, 아스팔트 포장, 교량 상판 균열 검사를 위한 사전 훈련된 VGG16 net을 인코더로 사용한 딥러닝 기반 균열 감지 모델을 제안하였다. Chun and Ryu(2019)은 데이터 수집과 주석화의 어려움을 해소하여 모델의 성능을 개선하기 위해 레이블이 지정되지 않은 대시보드 카메라의 이미지 데이터 세트에 심층 신경망 오토인코더 형태의 FCN을 사용한 의미론적 분할 모델을 이용한 준지도 학습이 적용된 방법을 제안하였다. Liu et al.(2019)은 콘크리트 균열을 감지하기 위해 처음으로 U-Net을 채택하여 기존 FCN보다 더 작은 훈련 세트로 더 높은 정확도에 도달하는 것을 확인하였다. Liu et al.(2019), Yang and Ji(2021)은 전이 학습에 기반한 균열 인식과 균열 의미 분할의 두 단계로 구성된 자동 픽셀 수준 균열 감지 방법을 제안하였는데, 균열 인식 단계에서는 미세 조정된 Vgg16 모델이 균열 이미지를 식별하고, Unet++ 모델을 통해 균열 이미지에 대한 픽셀 수준 의미론적 분할을 제공한다. 이상의 언급된 연구들 외에도 심층 합성곱 신경망을 이용한 포장파손 자동 탐지 분석 기법에 대한 많은 연구가 있으나, 포트홀, 균열과 같은 포장손상의 탐지에 주로 집중되어 왔다.
포장 패치의 탐지분석에 대한 연구는 파손에 대한 탐지 분류 모델의 한 유형으로 포함된 연구들이 있었으나, 픽셀 수준의 분할을 시도한 심도 있는 연구는 없다(Radopoulou and Brilakis, 2017; Zhu et al., 2022). 문헌조사 결과에 의하면 포장 패치를 중점적으로 탐지하는 연구는 후방 주차카메라로 촬영한 비디오 이미지에서 인식하는 방법이 유일하다(Radopoulou et al., 2013; Radopoulou and Brilakis, 2015). 기존 연구에서는 이미지 전처리를 적용하고, 히스토그램 기반의 임계값 결정 알고리즘을 통해 닫힌 형태의 패치를 인식하는 기법을 적용하거나, 패치와 주변 비패치 부분을 색상과 텍스쳐의 차이를 이용해 학습시킨 SVM 적용하고, 그 후에는 이미지 형태학적 닫힘 연산을 이용해 최종 패치 영역을 인식하고, 정량화하였다(Hadjidemetriou et al., 2015; 2016). 심층 합성곱 신경망 딥러닝을 이용한 연구는 없는 것으로 파악된다.
3. 방법론
3.1 제안된 방법론 요약
본 연구에서는 지역 도로관리기관의 실무 관점에서 포장파손에 대한 조치여부 확인 및 재파손 여부 등을 진단하기 위해 저비용의 자동화 시스템을 이용한 포장 패치부의 자동탐지 방법을 제시한다. 본 연구의 목적을 달성하기 위한 절차는 Fig. 1과 같다.
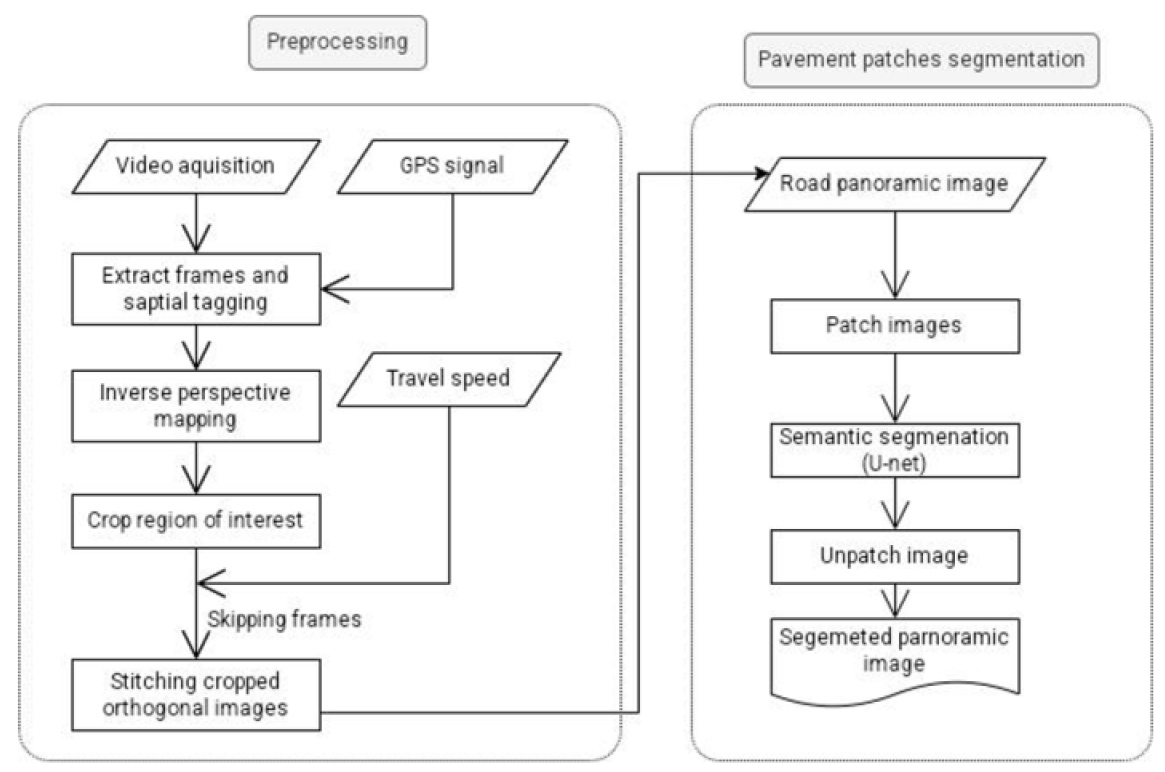
3.2 노면영상 취득
본 연구에서는 지역의 도로관리기관까지 보급이 가능 한 저비용이며, 넓은 노면 영역 이미지와 그 위치를 인지할 수 있는 주변 환경정보도 얻을 수 있는 차량의 전방을 바라보도록 설치된 비디오카메라를 이용해 영상을 수집한다. 카메라 렌즈와 촬영각도에 따라 얻을 수 있는 포장 노면의 범위가 달라지므로, 노면의 특징들이 소실되지 않는 정도의 적정 촬영 각도를 설정하고 고정 설치하여 도로 노면의 모습이 도로 경사의 영향 외에, 일정하게 확보되도록 한다.
3.3 이미지 전처리
비디오 영상에는 도로 외에도 다양한 지형물이 포함되어 있다. 포장 노면의 전체 조망을 위해서는 정사영 이미지의 연속적인 연결을 통한 파노라마 노면 이미지를 만들어야 한다. 본 연구에서는 전방에 설치된 카메라에서 촬영된 영상을 속도 가변적으로 추출하여 정사영 처리함으로써 노면 파노라마 이미지를 생성한다. 일반적인 파노라마 이미지 제작은 중첩으로 촬영된 이미지를 순차적인 이미지의 연결 부위를 결정하기 위해 정합 알고리즘을 사용하여 특징점을 추출하여 그들을 매칭 시켜 정합한다. 하지만 노면 이미지는 대부분 코너, 질감 등과 같은 특징점들이 많지 않아 이러한 방식을 적용하기는 어렵다. 따라서 본 연구에서는 주행속도에 기반하여 프레임을 추출하여 연결부위를 부드럽게 연결하는 방식을 적용한다.
3.3.1 주행속도 기반 프레임 추출
주행 중 촬영되는 동영상은 초당 수십장의, 15에서 120장까지의 프레임들로 구성된다. 따라서 개별 프레임들 간에는 중첩되는 부분은 주행 속도 식 (1)에 따라 달라지게 된다. 중첩되는 이미지에서의 탐지대상도 중첩되어 발생되고 이는 집계나 면적 등의 문제를 위해서는 중첩되는 부분을 걸러내야 하는 후처리가 필요하다. 중첩되는 부분을 없애고 최대한 실제 노면의 연속 파노라마 이미지로 생성하기 위해 속도에 기반한 프레임 선택을 적용하였다.
: 프레임당 차량 이동거리(m)
n : 초당 프레임수
s : 촬영 중 차량의 주행 속도(m/s)
3.3.2 Inverse Perspective Mapping
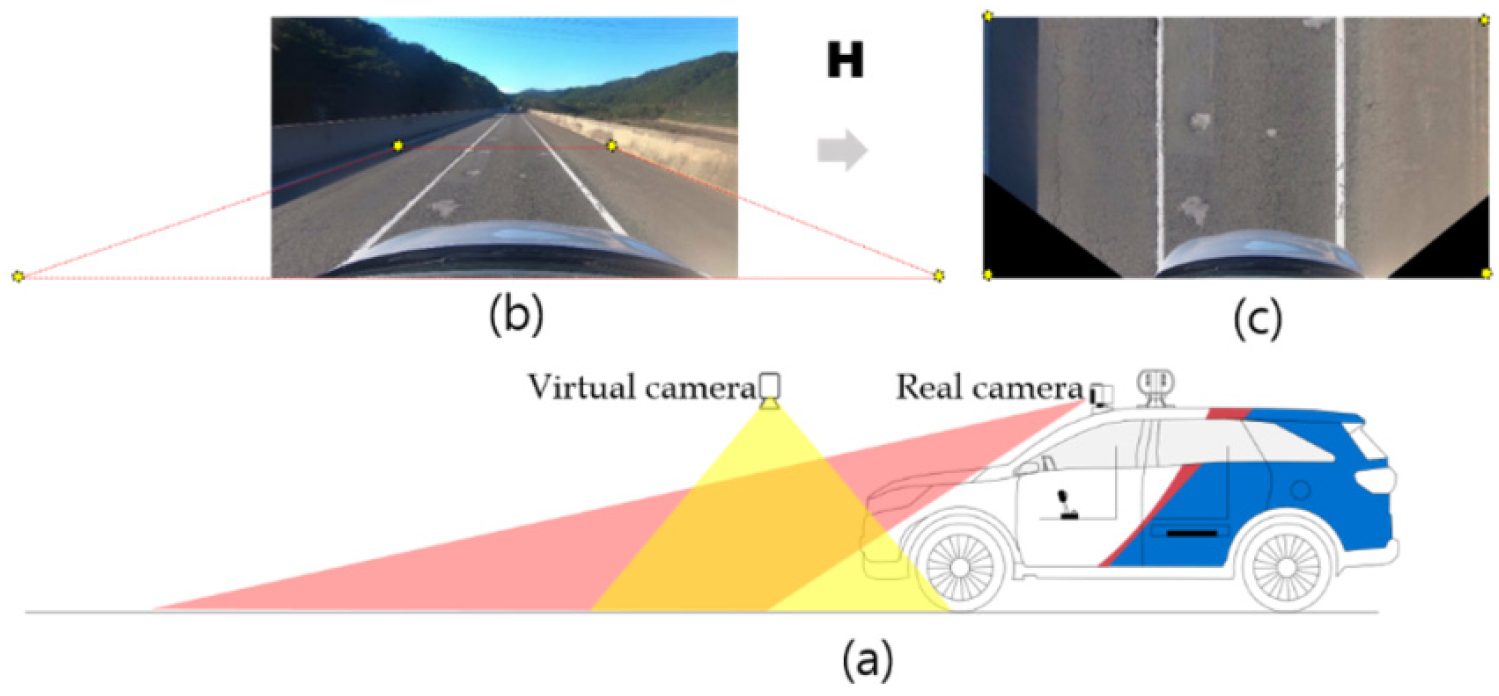
카메라는 3차원 공간의 물체를 2차원 평면에 매핑시키며, 원근 효과가 포함된 이미지를 만든다. 그러나 원근효과가 제거된 정사영 이미지에서 탐지하는 것이 탐지성능은 물론이고, 탐지결과의 해석에 더 유용해 주차보조, 자율주행 보조를 위한 차선인식 등 여러 응용분야에 적용되고 있다(Abbas and Zisserman, 2019). 전방을 바라보는 카메라에서 촬영한 이미지에서 원근 효과를 제거하고 탑뷰로 바라본 평면이미지로 변환이 가능한데, 이를 역투영변환(Inverse Perspective Mapping)이라 한다. IMP변환을 적용하려면 특정 조건이 가정된 구조화된 환경에서 사용할 수 있는데, 즉 2개의 평면 간의 관계를 나타내는 식 (1), 간략히 에서 호모그래피 행렬 H을 통해 간단히 변환할 수 있다. 두 이미지 평면에서 일치하는 한쌍의 x와 x’의 비동차(inhomogeneous) 좌표를 (x, y)와 (x’, y’)라고 했을 때, 식 (2), (3)과 같이 H의 요소를 파라메터로 갖는 선형식이 된다. 즉 자유도 8을 갖는 이미지 평면상의 4 기준 점들을 통해 H 행렬을 구할 수 있다. 도로면은 평면이며, 카메라는 고정된 위치에 있다는 가정하에 카메라의 내부, 외부 파라메터에 대한 사전 지식 없이 쉽게 계산될 수 있다(Hartley and Zisserman, 2004). 본 연구에서는 Fig. 2와 같이 차량의 전방 카메라로부터 취득된 원근 이미지(b)에서 차선 및 방호벽 경계부와 같이 직선이 명확한 부분에서 x 좌표를 택하고, 왜곡이 적은 노면 부분의 영역을 얻기 위해 카메라와 가까운 2개의 y좌표들의 수평선을 이용해 4점을 구하였다. 이를 통해 얻어진 호모그래피 행렬(H)를 구하고, 원근 효과가 제거된 탑뷰 이미지(c)를 얻을 수 있다.
3.3.3 Image Stitching
긴 연장의 포장 노면의 상태를 한눈에 조망할 수 있는 전역적인 뷰를 얻기 위해 카메라 동영상의 프레임내의 노면부분을 탑뷰로 추출하고, 연속된 조각 타일들을 부분적으로 중첩시키는 이미지 모자이킹(mosaicing)으로도 불리는 이미지 스티칭 기법을 적용한다. 일반적으로 이미지 스티칭의 주 프로세스는 특징 매칭, 정합 및 이음부 제거로 구성된다(Laraqui et al., 2017; Li et al., 2018; Wang and Yang, 2020). 그러나 빠른 속도로 이동하며 촬영되는 포장노면 이미지의 경우 주변 다른 물체(차량)의 움직임, 두드러지지 않는 텍스쳐 등으로 인해 기존의 방식, 예를 들면 상호정보(MI) 또는 픽셀간의 상대성(relativity)의 영역 기반 정합과 코너 탐지, SIFT, SURF 알고리즘과 같은 특징 기반 이미지 정합을 이용하는 것은 어렵다(Laraqui et al., 2017).
본 연구에서는 Fig. 3과 같이 시스템으로부터 얻어지는 GPS속도에 기반하여 초당 수십프레임 이미지로 이뤄진 영상에서 최적의 프레임을 선택하고 해당 프레임의 탑뷰 노면 타일을 쌓아 올리는 방식을 제안한다. 그리고 연결되는 조각 타일들의 부드러운 연결을 위해 두 이미지의 중첩부에 이미지 블렌딩 방법을 적용한다(Zhang et al., 2020). 그리고 각 타일에는 GPS 위경도 좌표가 매핑되어 노면 이미지의 실제 위치를 알 수 있으며, 변환되지 않은 전경이미지와 조합하여 실무에서 유용하게 활용될 수 있다.

3.4 딥 전이 학습을 이용한 의미론적 이미지 분할
3.4.1 U-net architecture
포장 패치는 파손부를 일정부분 잘라내고 포장 재료로 채워서 다짐해 놓은 부분으로 포트홀, 스폴링 등의 파손보다는 노면에서 넓은 범위를 차지한다. 본 연구에서는 최근 딥러닝 기반 연구들에서 객체탐지 보다 정밀한 픽셀단위의 의미론적 이미지 분할을 위해 주로 활용되는 완전 합성곱 신경망 U-net 아키텍처를 적용한다. U-net은 인코더 디코더 블럭으로 구성되며, 인코더 블럭은 VGG와 같이 여러 개의 합성곱 레이어를 반복하며 특징을 추출하는 수축 경로이다. 그리고 디코더 블럭은 업샘플링을 통해 해상도를 증가시키며, 더 정밀한 지역화를 위해 수축경로의 고해상도 특징맵이 연결되는 확장경로로 불린다. 기존 FCN과 비교하면, 업샘플링시 보다 많은 채널을 가져 이미지 컨텍스트 정보를 전파한다는 것과, 합산이 아닌 연결 연산을 사용하는 것, 여러 층의 업샘플링과 학습되는 합성곱 필터들이 수정되었다고 할 수 있다(Ronneberger et al., 2015).
3.4.2 Transfer Learning
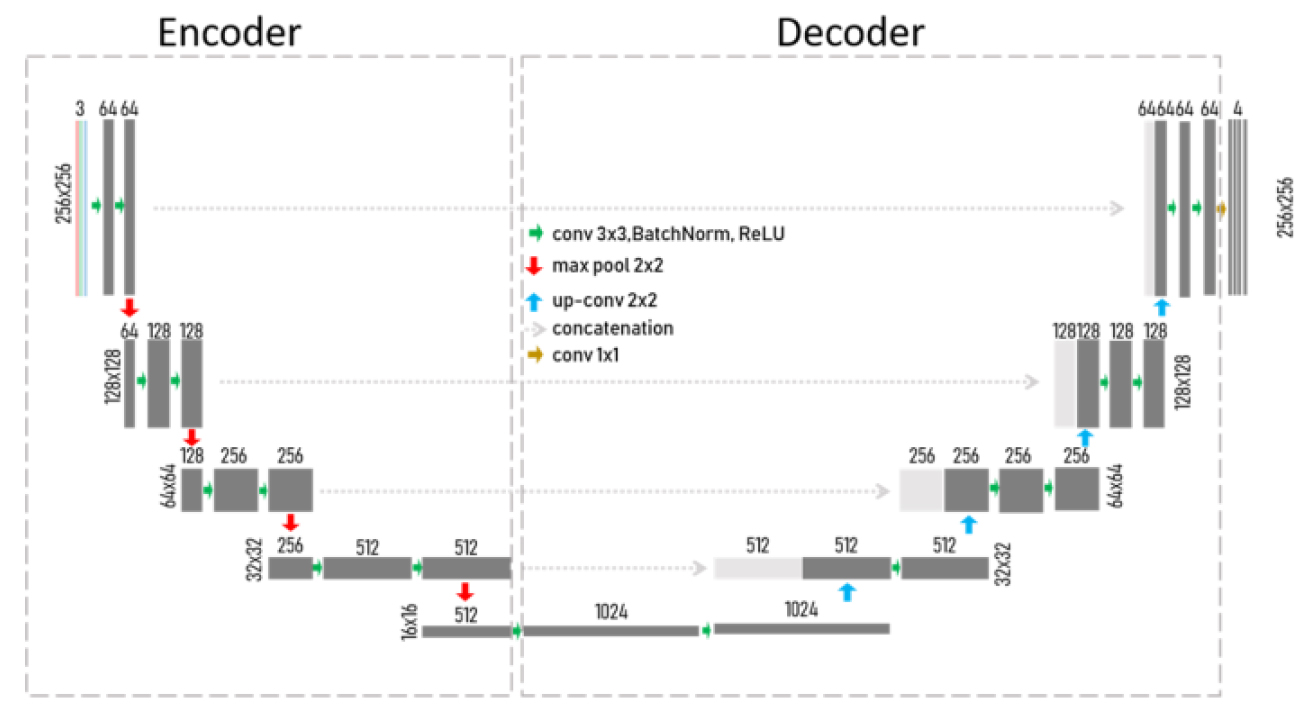
픽셀 수준의 이미지 분류를 위한 심층 합성곱 신경망은 훈련을 통해 좋은 성능의 일반화 모델을 얻기 위해서는 다양한 특징을 포함하는 많은 수의 주석화된 데이터를 필요로 한다. 그러나 현실적으로 해당 도메인 분야에 특화된 학습데이터 구축에는 인적, 물적으로 많은 비용이 따른다. 본 연구에서는 Fig. 4에서 보는 바와 같이, 입력 이미지에서 특징을 추출하는 기능을 하는 수축 경로를 여러 깊이와 스케일을 갖는 백본으로 대체하고, 대규모 데이터셋, Imagenet으로 사전 학습으로 얻어진 가중치를 활용하는 전이학습을 적용한다. 그리고 원본 해상도로 재현하는 확장 경로에 대해서는 노면 이미지 학습데이터를 이용하여 훈련하여 훈련의 효율과 성능을 향상시킨다. 입력 이미지데이터가 미리 훈련된 네트워크를 통과하면, 특징이 추출되고, 소프트맥스 함수를 통해 개별 픽셀들의 분류 클래스에 대한 독립적인 확률값을 출력하게 된다. 본 연구에서는 최고의 성능을 보이는 인코더 네트워크를 찾기 위해 여러 연구를 통해 좋은 성능을 보이는 것으로 나타난 다양한 백본들을 적용하였다.
4. 현장시험 실증을 통한 성능평가
4.1 Dataset
본 연구에서는 도로점검차량(SUV) 상단에 영상카메라를 설치하고 실제 주행을 통해 얻어진 영상을 이용하여 제안된 방법론을 적용하여 노면 파노라마 이미지를 얻었다. 노면 파노라마 이미지는 카메라의 촬영 각도와 화각에 의해 넓은 범위, 3차로까지의 노면영역 확보가 가능하나, 적정 픽셀 분해능을 유지하기 위해 2차로까지를 범위로 한다. 패치의 유형으로는 채워지는 재료에 따라 아스팔트 콘크리트와 시멘트 콘크리트로 구분된다. 그리고 옆차로에 차량이 있을 경우 노면을 가리게 되어 노면 패치의 존재여부 판독을 불가능하게 하는 장애물이다. 이에 따라 Fig. 5와 같이 아스팔트 패치, 콘크리트 패치, 자동차의 3개의 클래스로 주석화 하였다. 모델을 강건하게 만들기 위한 데이터 증강을 위해 수직, 수평, 그리고 랜덤 컨트라스트 3가지로 변형하여 데이터 증강을 하였다. 또한 학습의 불필요한 자원 낭비를 막기 위해 패치상에 5% 미만의 주석이 있는 경우는 학습데이터에서 제외하였다. 학습과 검증의 비율은 각각 70%, 25%로 나눴으며, 총1차로 패치의 경우 훈련데이터 9,760 검증데이터 3,487, 2차로 패치의 경우 3099, 1,107의 이미지를 사용하였다. 나머지 5%는 훈련시 모델의 테스트용으로 사용하였다.

4.2 모델훈련
실험을 위해 Intel i7 CPU, an NVIDIA Geforce GTX 3090ti GPU, 64 GB 메모리의 컴퓨터와 오픈소스 프레임워크인 Keras and Tensorflow를 이용해 Ubuntu 20.04 환경에서 파이썬으로 구현하였다.
훈련데이터를 입력하여 주어진 네트워크를 통해 예측된 결과와 실제 정답치와의 차이, 손실 함수는 탐지대상과 배경 클래스간의 극단적인 불균형을 다루기 위해 제안된 Focal loss(Lin et al., 2020)와 두 샘플의 유사성을 측정하는 Dice 계수를 직접적으로 최적화하는 Dice loss의 조합을 사용하였다. 그리고 손실을 최소화하기 위한 매개변수를 찾기 위한 최적화 알고리즘으로 Adam을 사용하였다. Adam은 그래디언트 하강 방법에 기초하며 모멘텀 알고리즘과 RMSprop알고리즘을 조합한 것이다(Kingma and Ba, 2015). 본 연구에서는 학습률은 0.000001, 1차, 2차 모멘트는 0.9와 0.999을 사용하였다. 네트워크는 각 픽셀을 2개의 패치와 1개의 장애물(차량)으로 분류하는 것으로 목적으로 하므로, 최종 출력 층은 소프트맥스를 통해 클래스에 대한 독립적인 확률값이 만들어진다. 안정적인 수렴 여부를 확인하기 위하여 8 미니배치를 이용해 300 에포크로 훈련하였다. 컴퓨팅 자원의 제한으로 입력이미지의 크기는 256 × 256으로 하였다.
4.3 Evaluation metrics
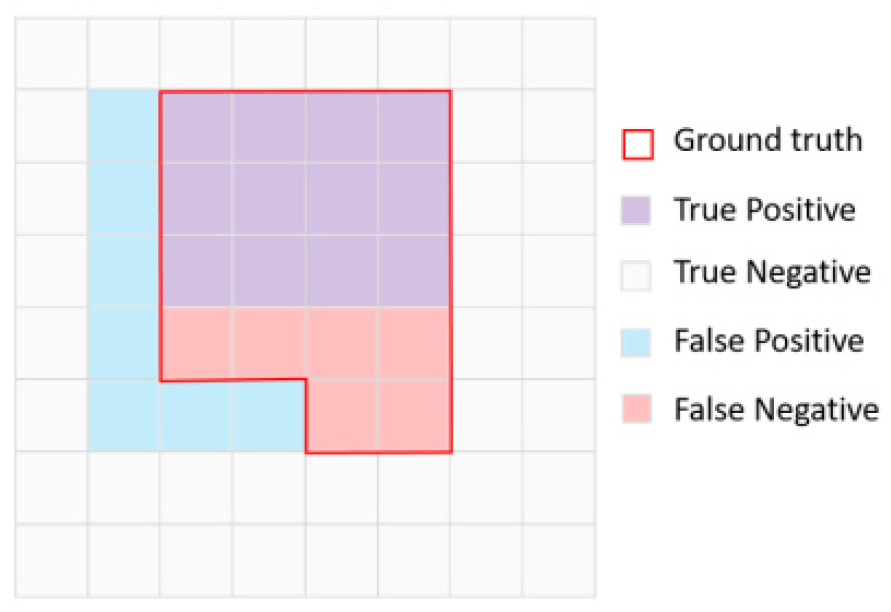
기본 U-net과 전이학습 모델들의 이미지 분할 성능 평가를 위해, 잘 알려진 accuracy, IoU score, precision, recall, dice score를 사용하였다. Fig. 6를 예시로, 각 지표의 최종 값은 개별 클래스별로 식 (4), (5), (6), (7), (8)을 통해 계산되고, 모든 클래스에 대해 평균한 값이 된다.
4.4 결과분석
4.4.1 훈련 성능
기본 U-net을 포함하여 총 8개의 모델을 1차로 패치와 2차로 패치의 2개 데이터셋을 이용하여 훈련하였다. 훈련 결과는 Fig. 7과 Table 1에서 확인할 수 있다. 최적의 파라메터가 수렴해가는 것을 손실함수 그래프를 통해 확인할 수 있다. 2차로 데이터셋에 더 빠르게 수렴하며, 성능도 1차로에 비해 2차로가 더 우수하다. 이것은 비교적 크기가 큰 패치의 경우 2차로 범위에서 그 특징의 추출이 더 용이하기 때문으로 추정된다. 기본 U-net 보다 resnet, efficientnet 계열의 전이학습 모델의 성능이 더 우수하다. Table 1은 인코더 네트워크에 사용된 백본에 따른 훈련 성능과 손실 값을 나타낸 것으로, 1차로 패치 입력 이미지들로 학습한 모델에서는 resnet152가 accuracy 0.995, mIoU 0.968, precision 0.503, recall 0.990, f1 score 0.978로 가장 우수했다. 2차로 패치 입력 이미지에서도 해당 모델이 accuracy 0.991, mIoU 0.952, precision 0.535, recall 0.978, dice score 0.967였다. 다음으로는 renet101, efficientnetb7, efficientnetb0, resnet34, inceptionv3, standard 순이었으며, vgg16은 다른 모델들에 비해 성능이 두드러지게 낮았다.
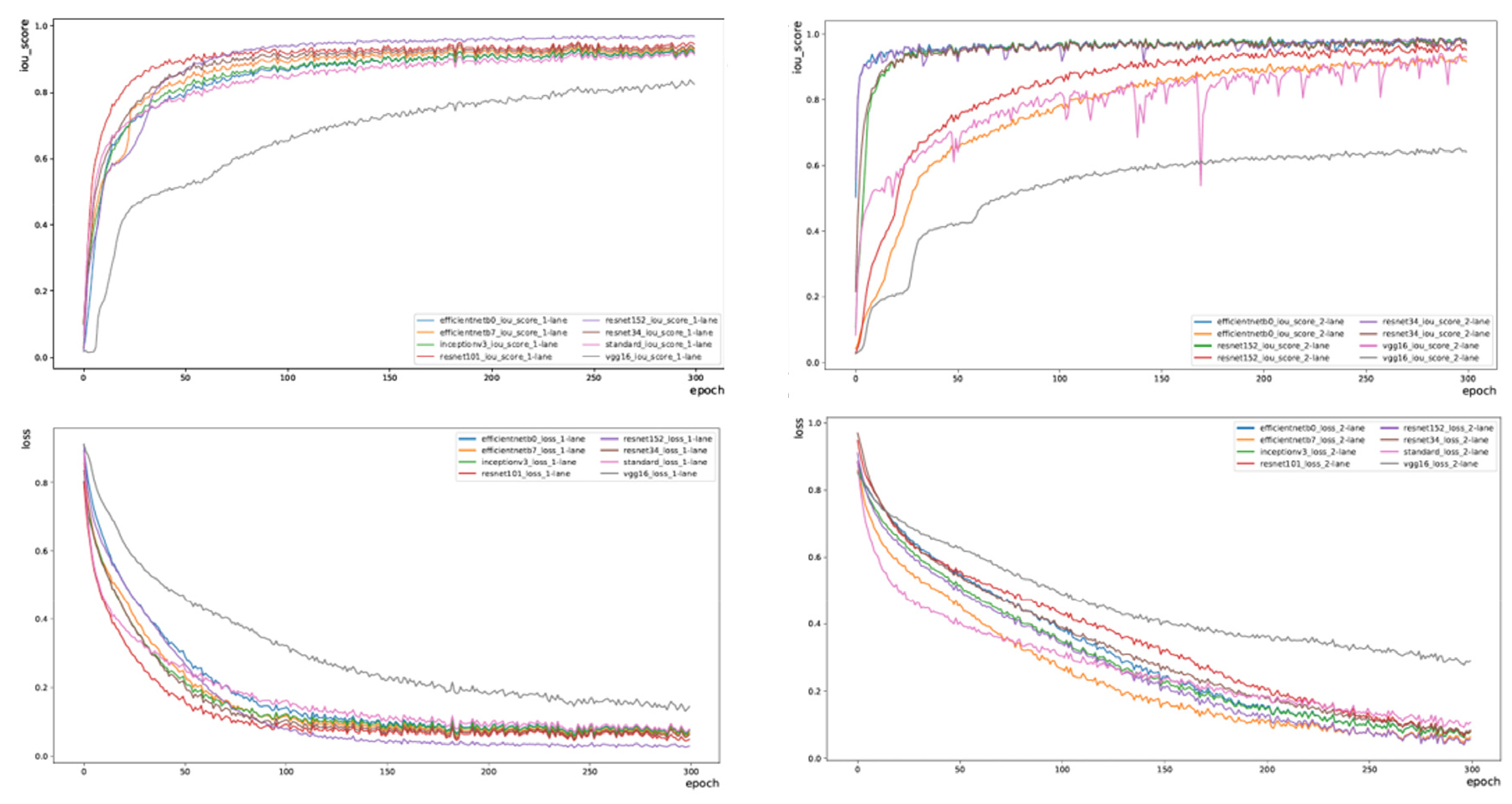
Table 1.
Performance and training loss with various backbones
4.4.2 테스트 성능
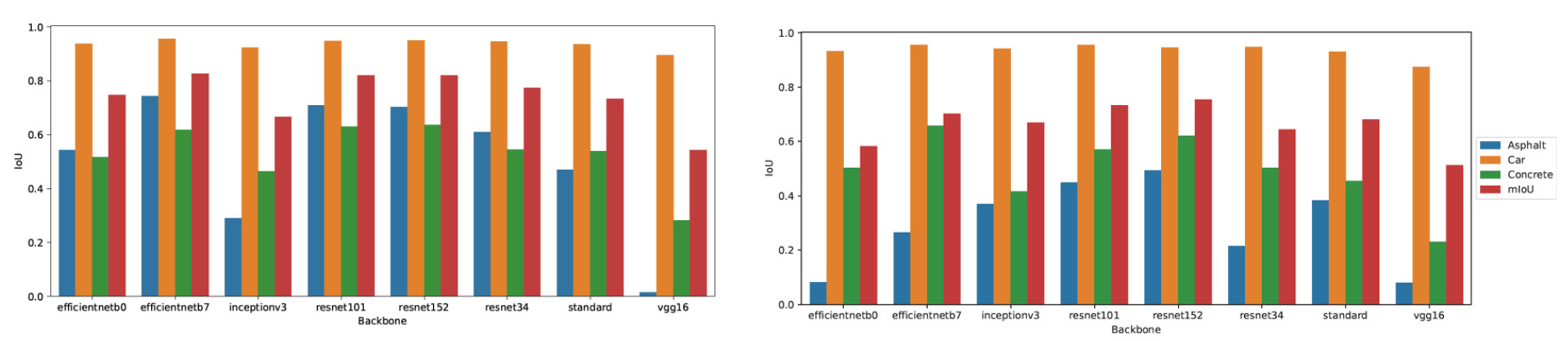
훈련과 검증을 통해 생성된 모델의 성능을 테스트하기 위해, 새로운 구간에서 촬영된 영상을 이용하여, 연구에서 제안한 방법으로 적용하여 스티칭된 노면 이미지를 생성하였다. 약 10 km의 스티칭 된 노면 이미지에 대해 1차로 패치와 2차로 패치로 나누어 백본별 모델을 이용해 예측하였다. Table 2에서는 인코더 네트워크의 백본 모델별로 성능지표 mIoU를 평가하였다. 이때 모델 훈련단계와는 달리 efficientnetb7 인코더 백본, 2차로 패치 적용했을 때 mIoU가 0.827로 가장 높게 나왔으며, resnet152 백본을 2차로 패치 적용시에는 mIoU가 0.821로 나타났다. Fig. 8에서 보는 바와 같이 클래스별 분류 정확도에서는 비교적 넓은 면적의 두드러지는 특징을 가지는 차량의 성능이 가장 높았으며, 아스팔트 패치의 경우 2차로 패치에서, 콘크리트 패치는 1차로에서 상대적으로 높은 성능을 보였다. Fig. 9는 실제 원본 노면이미지와 이에 대한 마스크 이미지(a)와, 입력 이미지의 차로에 따른 백본 모델별 예측결과(b)~(i)를 나타낸 것으로, efficientNetb7(c), resnet152(g)의 우수한 이미지 분할 성능을 확인할 수 있다.
Table 2.
Performance of test images

5. 결론 및 논의
본 연구에서는 저비용 비전 시스템을 통해 수집된 이미지의 영상 처리와 의미론적 이미지 분할 네트워크 U-net을 적용해 포장 패치부의 자동 탐지 방법을 제안하였다. 표준 합성곱층 파라메터를 직접 훈련하는 것과, 인코더 부분에 Imagenet 데이터셋으로 사전 학습된 파라메터를 적용한 백본을 활용해 지식 전환 방식을 적용하여 훈련한 결과를 비교한 결과, 상대적으로 깊은 레이어를 가지는 resnet152,101과 efficientnetb7이 가장 우수한 성능을 보이는 것을 확인하였다. 또한 입력 이미지의 차로 영역 범위는 상대적으로 적은 수의 학습데이터임에도 불구하고, 2차로 영역이 1차로의 영역보다 보다 우수한 패치 탐지성능을 나타냈다. 학습데이터에 포함되지 않은 새로운 도로 구간의 영상이미지로 테스트한 결과, mIoU 0.827의 성능을 나타내어, 본 제안 방법의 우수성과 실무 적용 가능성을 확인하였다. 차량의 전방향 촬영 영상의 처리를 통해 얻어진 수직 방향 노면 이미지는 파손의 탐지와 정량화 등 포장상태 파악에 필요한 정보의 추출이 용이하며, 시간 경과에 따른 상태변화 정보를 일관성 있게 이력화 하는 것도 가능해진다. 또한 카메라 촬영 영역에 포함되는 여러 차로의 포장노면을 한 번에 조망하는 것이 가능해 점검의 효율도 높아진다. 영상 이미지에 GPS좌표 정보를 매핑하고, 무선통신을 통한 전송과 후처리 분석시스템을 구축한다면 포장점검 자동화의 완성도를 높일 수 있을 것이다. 이러한 장점에도 불구하고 주행 중 촬영되는 노면 이미지의 낮은 선명도, 급격한 오르막 및 곡선부, 그리고 주행 중 횡방향 위치 이동 등 역투영 변환시의 가정이 크게 벗어나는 경우 자연스러운 수직 노면 모양이 얻어지지 않는 한계를 여전히 지니고 있다. 향후 연구에서는 실무 활용성을 보다 높일 수 있도록 고품질의 이미지의 취득과 자동 탐지 성능 향상, 시간경과에 따른 파손부의 변화, 보수 여부 등을 자동으로 탐지하고 이력화할 수 있는 방안에 대한 연구 방향을 가질 것이다.
