

1. 서 론
2. 연구방법
2.1 시뮬레이션 컴퓨팅 환경
2.2 시뮬레이션 세팅
2.3 학습 방법 및 시나리오
3. 결과 및 고찰
3.1 학습에 따른 보상/처벌 결과
3.2 시뮬레이션 결과
4. 결 론
1. 서 론
드론의 활용도는 시대의 발전에 따라 그 범위가 넓어지고 있다. 군사적 목적 중 정찰 및 감시, 군사 작전 등에서 해외 언론을 통하여 쉽게 그 활용을 접할 수 있다(신재길, 2022). 이 외에, 물류 및 배송(Jung and Kim, 2017), 작물 모니터링(함건우 등, 2019), 산불 감시(이민재 등, 2022) 등 다양한 산업분야에서 활발하게 활용되고 있다. 건설분야도 드론을 적극 활용하고자 활발하게 연구하고 있다. 인프라시설은 대부분 교량, 항만, 댐과 같은 스케일이 큰 구조물이 절대적으로 많다. 교각의 경우, 인력을 활용한 손상부 탐지를 실시하고자 한다면, 인부가 실제로 와이어로프에 의존하여 직접 손상부까지 도달해야 한다. 이 경우, 와이어로프에 손상이 발생한다면 인명피해로 이어지며, 안전하게 손상부에 대한 조사를 마치더라도 그 인부에 대한 인건비가 상당히 투자된다. 사람의 안전과 경제적 측면을 고려할 때, 드론의 활용은 이점이 많다. 이성진 등(2022)은 드론을 활용하여 케이블지지교량의 안전점검 사각지대를 극복하기 위한 연구를 수행하였다. 주탑 외부점검을 위하여 시범적으로 운행하였으며, 사람이 직접 관찰하기 어려운 구역까지 성공적으로 손상 및 균열 탐지에 성공하였다. 이 외에, 비탈면 모니터링(이강현 등, 2022), 태양광 발전소 고장 점검(김동균 등, 2016) 등과 같이 적용 범위가 넓다. 드론을 다수 운영할 경우에는 모니터링 가능 영역이 현저히 넓어질 것이다.
도로포장 관리 측면에서도 드론은 충분히 그 이점을 발휘할 수 있다. 가장 대표적으로 도로포장에서 자주 발생하는 균열, 포트홀 탐지가 있다. 현세권・도명식(2021)은 합성곱신경망 기반 사전학습 모델을 활용하여 카메라와 연동 후 실시간 도로포장 상태를 평가하는 기술을 개발하였다. 카메라를 드론에 탑재하고 모바일 환경에서 구동이 가능하도록 시스템을 최적화하였다. 결과적으로, 도로포장 표면의 손상 탐지는 성공적으로 수행되었으며, 드론의 도로포장 관리 측면에서 그 가능성을 보였다. 송미화・길흥배(2022)은 열화상카메라를 드론에 탑재하고 이를 활용한 교면포장 품질관리 기술에 대해 연구하였으며, 정갑용・박준규(2021)은 드론과 라이다를 활용한 포장의 평탄성을 조사하는 연구를 수행하였다.
이미지 및 영상 기반 처리를 통한 손상 모니터링에 관한 사례는 쉽게 찾아볼 수 있다. 하지만, 드론의 경로 최적화나 고도를 자유롭게 변경하는 공중 자율비행에 대한 최적화 연구는 쉽게 찾아볼 수 없다. 주된 이슈는 보통 손상에 의한 인명피해나 사고에 대한 중요성이 강조되기 때문이며, 동시에 경로 최적화 자체의 기술 구현 난이도가 높은 부분도 있다. 보통 이동 경로와 관련된 인공지능 기술은 강화학습을 주로 사용한다. 하지만, 도로포장 관련 강화학습 기술에 대해서 사례를 찾아보면 쉽지 않다. 먼저, Paraschos et al.(2025)이 수행한 도로포장 유지보수 비용 최적화에 대한 강화학습 연구가 있다. 교통량, 손상도 등을 에이전트가 학습하여 최적의 비용을 산출하는 방식으로 강화학습이 활용되었다. 국내에서는 도로포장 분야에서 드론과 강화학습을 연계한 연구사례를 찾기 힘들다. 주로 로봇(최보경 등, 2025), 컴퓨터그래픽스(조시훈・김태영, 2021) 관련 연구에서 찾아볼 수 있다. 이처럼, 도로포장에서 자율적으로 강화학습을 활용하고 경로 최적화를 구현하기 위한 연구가 부족한 실정이다. 첨단 기술의 최전선에 있는 로봇, 컴퓨터, 인공지능 분야에서만 활용되고 있는 강화학습이지만, 효율적인 도로포장 관리를 위해서 건설분야도 적극적으로 강화학습을 활용하는 사례가 증가해야 한다.
본 연구는 드론을 직접 활용한 사례가 아니다. 드론의 경로 최적화 구현을 위한 시뮬레이션 연구로써 수행되었다. 드론의 경로 난이도를 높여서 수행하기 위하여 산악지형이 많은 한탄강 생태경관단지 근처의 위도 38.08499, 경도 127.2299의 위치를 시작점으로 하여 위도 38.08827, 경도 127.1794의 위치를 도착점으로 하였다. 총 시뮬레이션 직선 거리는 약 4.426 km이며, 고도는 시작점 해발 높이 396 m를 시작으로 도착점 해발 높이 316 m로 설정하였다. 시뮬레이션 지형 중간에는 해발 최대 높이 616 m의 산악구간을 통과해야 하는 복잡한 지형을 장애물로 설정하였다. 모든 시뮬레이션은 심층 강화학습(Deep Reinforcement Learning, DRL)을 활용하였다.
2. 연구방법
2.1 시뮬레이션 컴퓨팅 환경
Table 1은 본 연구에서 사용한 컴퓨터의 사양을 정리한 표이다. DRL을 활용하기 위하여 그래픽처리환경(Graphic Processing Unit, GPU)에서 연구를 수행하였다. 시뮬레이션의 영역이 넓으며 처리해야 할 데이터가 많기 때문에 병렬처리를 통하여 모델의 학습 속도를 확보하는 전략으로 수행하였다. 특히, CuPy를 활용함으로써 CPU 연산을 GPU로 강제 할당하여 단순 연산 처리를 병렬 연산으로 처리속도를 증가시켰다.
Table 1.
Computer specifics
| Core | AMD Ryzen 9 7945HX (16 cores) |
| GPU | NVIDIA Geforce RTX 4070 Laptop (4,608 CUDA cores, VRAM 8 GB) |
| Memory | DDR5 32 GB RAM |
| Environment | CUDA – GPU Utilized with CuPy |
2.2 시뮬레이션 세팅
구글지도에서 국내 환경의 지도 API를 활용하기가 매우 어렵다. 그 이유는 군사적인 이유로 인하여 제대로 지도 데이터를 활용할 수 없기 때문이다. 이를 극복하고자, Python의 SRTM 라이브러리를 활용하였다. SRTM 라이브러리는 미항공우주국의 Space Shuttle Radar Topography Mission에서 데이터를 파싱하고 활용할 수 있도록 제작된 라이브러리이다. 즉, 위도 및 경도에 따른 해발고도 데이터까지 활용할 수 있기 때문에, 본 연구에 가장 적합한 라이브러리로 판단하였다. SRTM에서 제공하는 데이터는 컴퓨터의 메모리를 상당하게 차지한다. 따라서, 위도, 경도, 고도 데이터를 각각 변수로 설정하고 실수 데이터로 반환하여 사용하였으며, 이 데이터는 추후 시뮬레이션 경로를 3차원으로 시각화 하는데 사용되었다.
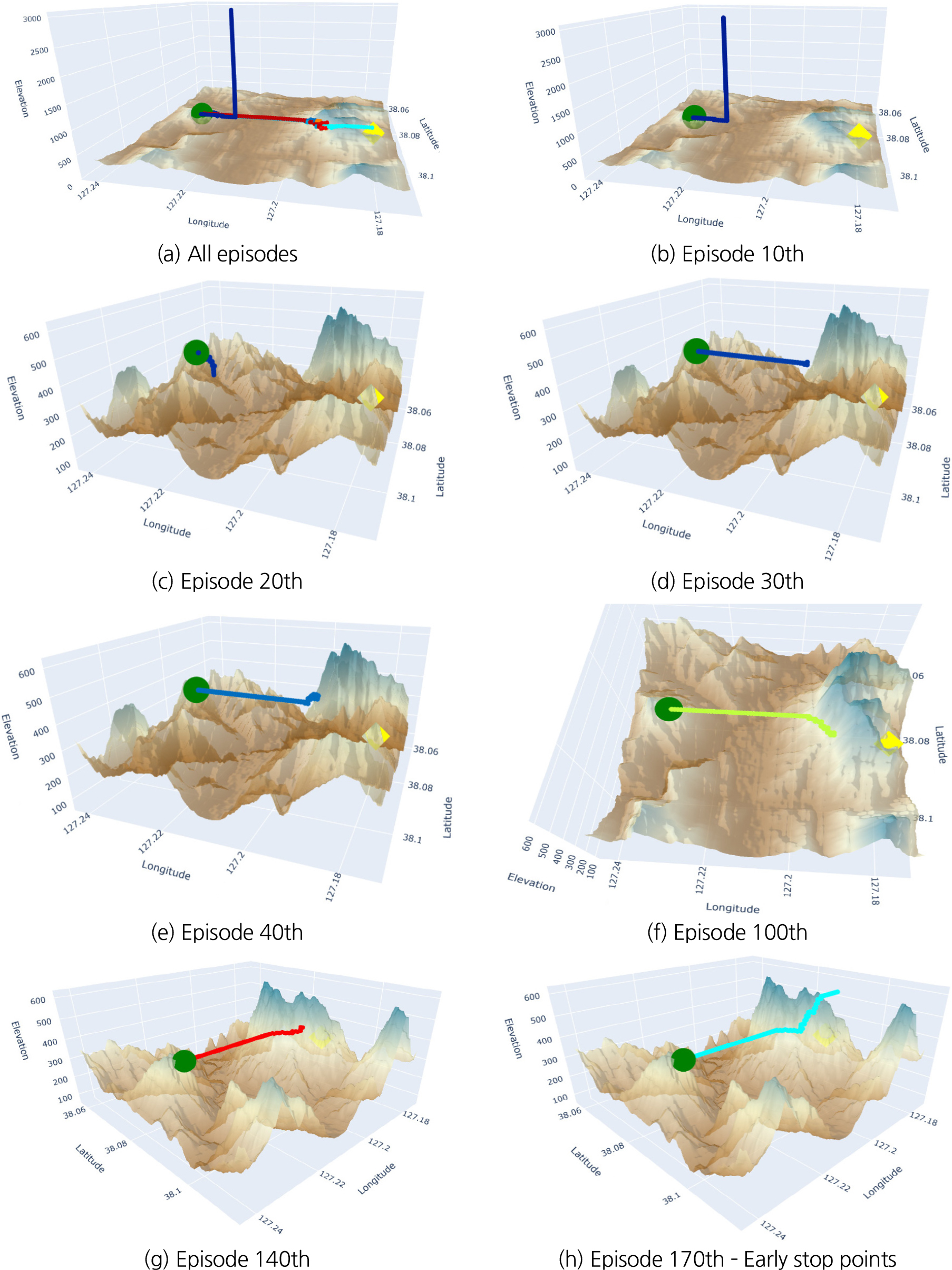
시뮬레이션 위치는 앞서 언급한 시작점 38.08499, 127.2298 및 396 m에서 도착점 38.08827, 127.1794 및 316 m에 대한 경로 최적화 시뮬레이션이다. Fig. 1은 시뮬레이션 위치와 그 지형의 3차원 지도이다. Fig. 1(b)에서 초록색 점은 출발점, 노란색점은 도착점을 나타낸다.
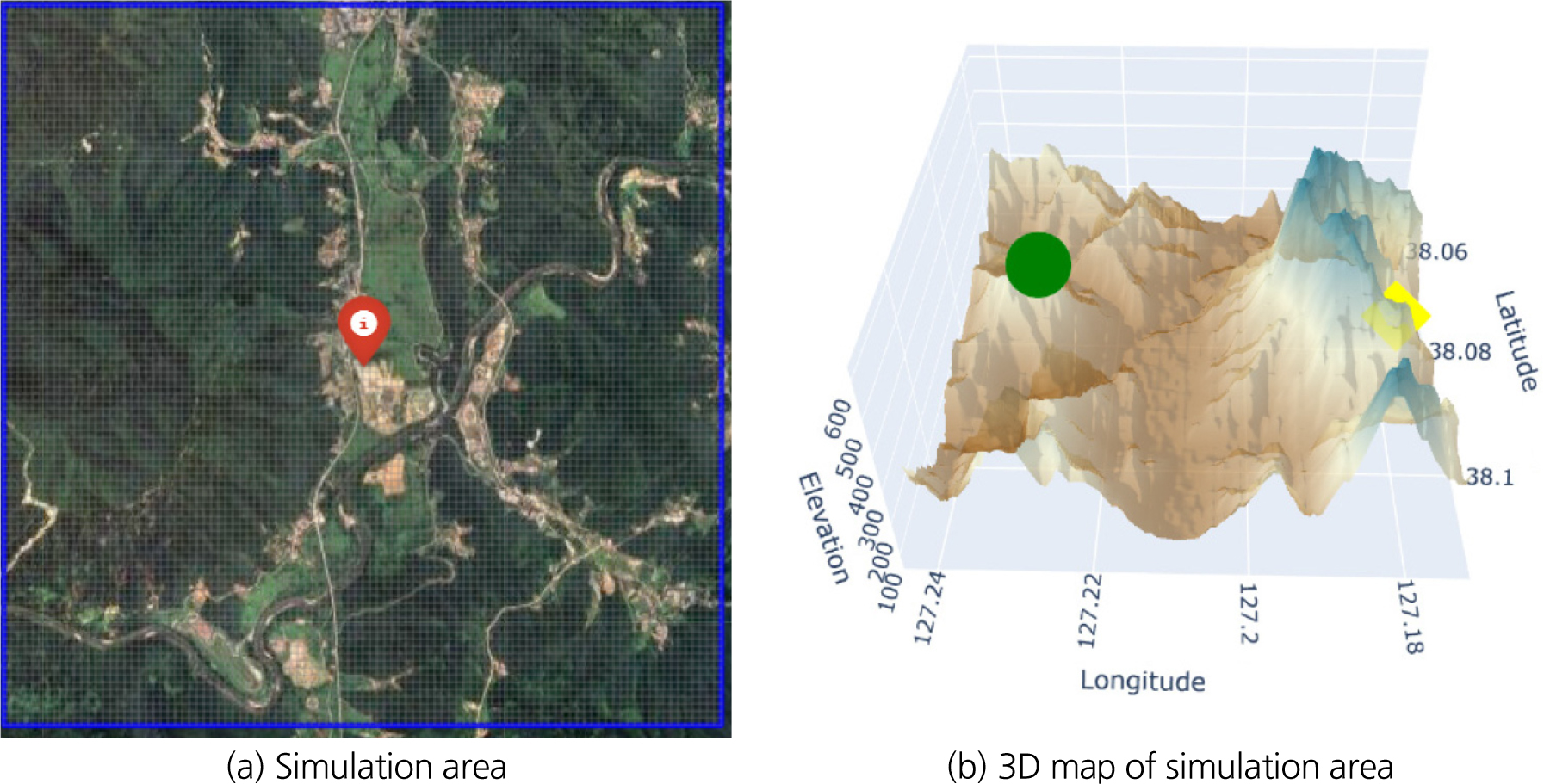
드론이 비행하는 시뮬레이션을 구현하기 위해서 구역을 그리드로 분할이 필요하며, DRL이 활용할 과도한 메모리를 고려하여 Fig. 1(a)의 영역을 100 × 100개수의 셀 그리드로 분할하였다. 즉, 영역 안에서 시뮬레이션 될 교차점의 최대 개수는 10,000개이다. 풍속 및 풍향, 날씨 조건은 고려하지 않았다. 산악지형은 사람의 활동반경의 환경과 같이 평평하거나 예측되는 고도를 가지지 않는다. 무작위한 지형의 고도 및 경로가 강화학습에 대한 난이도를 높이고, 보다 복잡한 환경을 학습하기 알맞은 환경으로 판단하여 해당 위치를 선정하였다.
2.3 학습 방법 및 시나리오
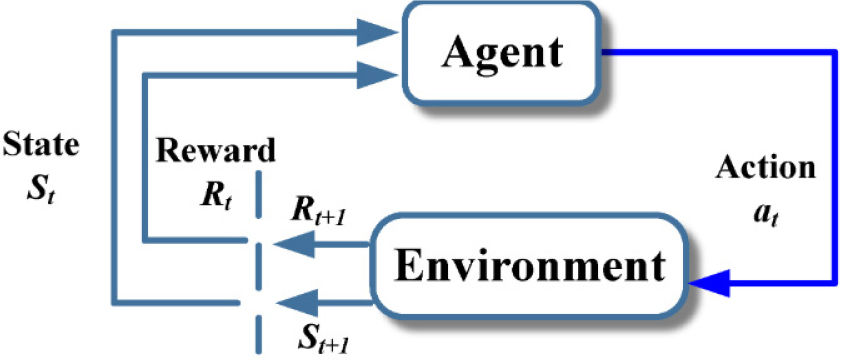
DRL의 핵심 연산은 Deep-Q Learning(DQL) 방식이다. 일반적인 Q-learning은 Fig. 2와 같이 객체(Agent)가 행동(Action)을 하고 환경(Environment)에 반응을 전달하며 그 반응에 따른 상태(State)가 업데이트되고, 반응에 따른 보상(Reward) 혹은 처벌(Punishment)이 이루어진다.
이 원리를 심층신경망과 연결한 강화학습이 DRL이며, 핵심 원리인 DQL은 DQ 네트워크로써 승화된다. Fig. 3이 이 원리를 잘 나타내었는데, Fig. 2와 다른 지점은 더욱 복잡한 환경을 다룰 수 있으며, 객체 내부에 심층 신경망을 구현하고 이를 학습한 객체는 행동이 바뀌게 된다. 무엇보다, 복잡한 환경조건을 다루어야 하는 본 연구에서 가장 적합한 모델이라 판단하였다. 학습 과정에서 과적합을 방지하기 위한 안전장치도 구현하였다. Table 2는 본 연구의 시뮬레이션을 구현하기 위한 DRL 세팅이다.
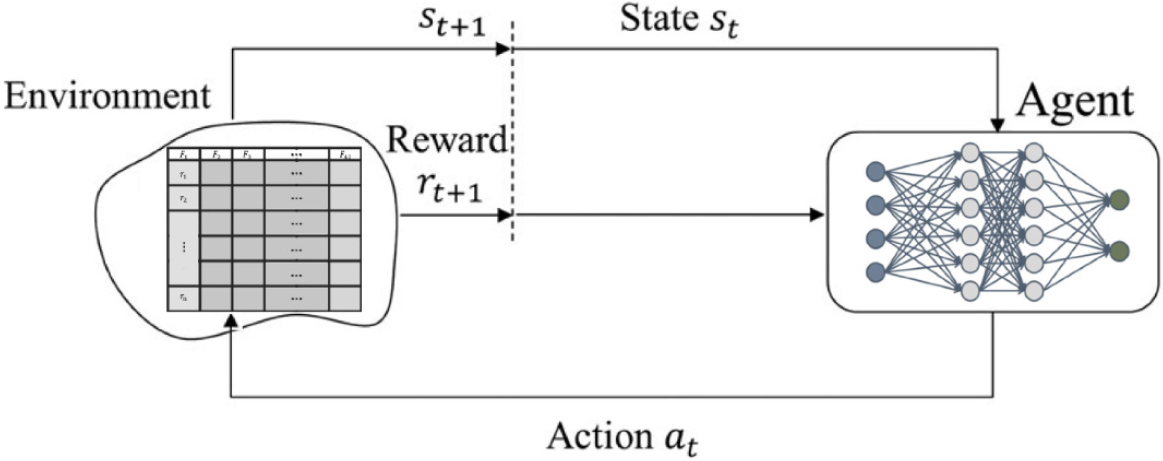
Table 2.
Parameter setting of DRL
파라미터의 세팅 자체는 간단하지만, DQ네트워크를 구성하는 부분에서 많은 연산처리를 구현해야 한다. 또한, 고도 및 평면의 비행 제한길이를 설정함으로써 무한히 발산하는 현상을 사전에 방지하였다.
3. 결과 및 고찰
3.1 학습에 따른 보상/처벌 결과
Fig. 4는 본 연구에서 모니터링 된 가상의 드론이 모델에서 축적한 보상/처벌 점수 그래프이다. 드론의 비행은 보상을 받아 적절한 위치로 이동을 시작할 때, 항상 정답의 위치로 가깝게 다가가지 않고 랜덤하게 움직임을 보여준다. 가로, 세로, 높이의 3차원 시뮬레이션으로 가로, 세로 방향이 정답에 다가가도, 산악지형과 같은 장애물과 닿아 추락하는 시뮬레이션이 나온다면 고도에서 최적화를 이루지 못한 것이므로 처벌을 받는다. 총 170번의 시뮬레이션동안 초기 50번 시뮬레이션 까지는 갈피를 잡지 못하는 모습을 보인다. 이후 일부 양수로 전환된 보상값을 확인한 순간부터 급격하게 정답율이 올라가는 것을 확인할 수 있다. 물론, 이후에도 고도 및 경로를 최적화하면서 처벌구간이 존재하지만, 초기 50번 시뮬레이션 구간처럼 음수값에 머물지 않는다. Table 2의 ε은 경로를 찾기 위한 경우의수로 이해하면 좋은데, 정답에 가까워질수록 경로는 짧아지고 경우의 수는 줄어든다. 동시에, 연산에 필요한 시간 단계도 줄어든다.
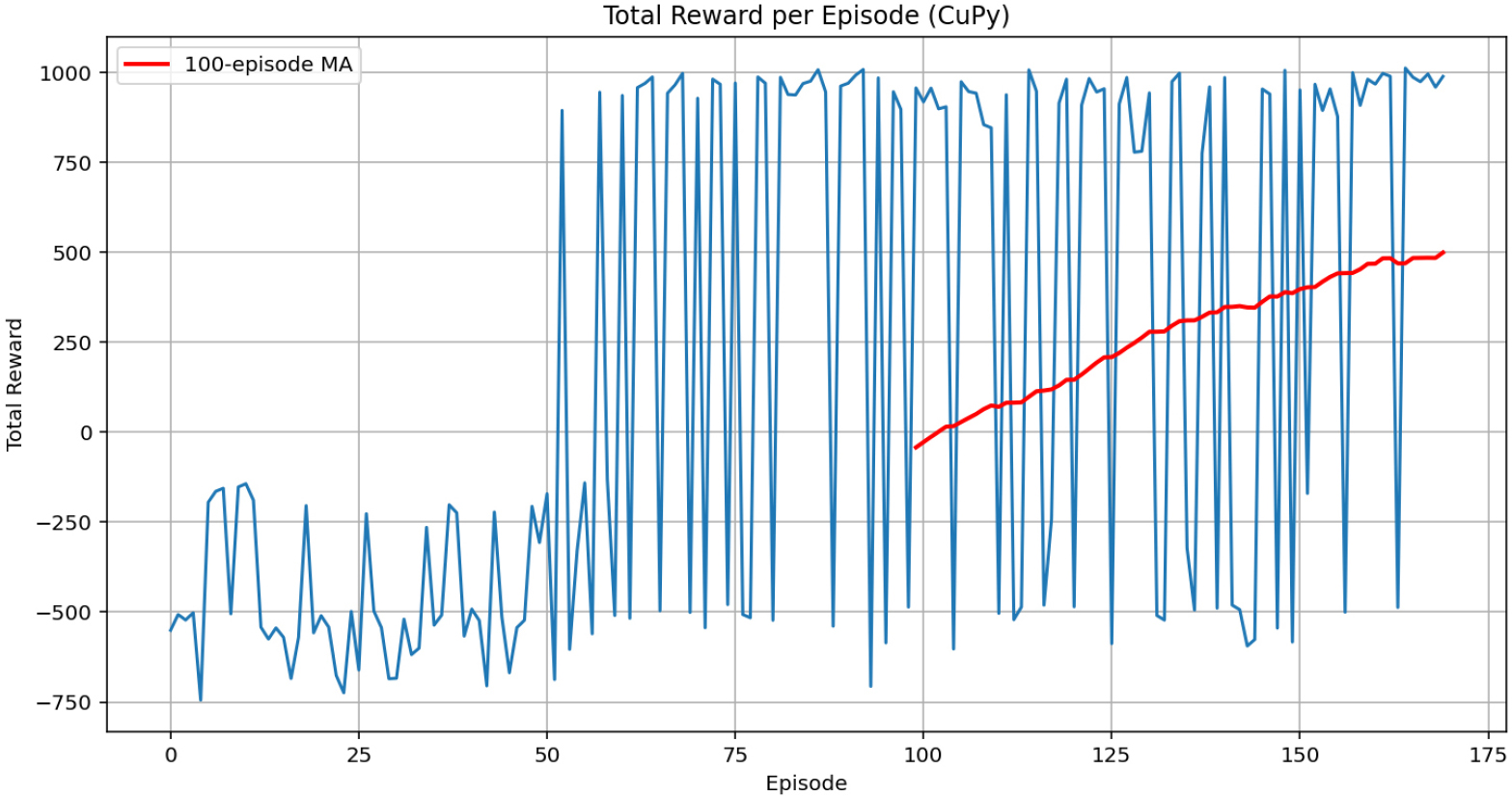
본 연구의 시뮬레이션은 170에서 조기 종료되었는데, 이때의 보상은 약 1,000점이었으며, ε값은 0.057로 0.06 미만 값을 달성하여 최적의 모델이 170 에피소드에서 등장한 것으로 간주되었다. Fig. 4의 붉은선은 100 에피소드당 보상/처벌 평균 점수로 이해하면 된다. 평균점수가 지속적으로 증가하는 모습으로 보아, DRL 학습은 정답에 가까워지도록 학습한 것이 맞음을 확인할 수 있다.
3.2 시뮬레이션 결과
Fig. 5는 본 연구의 시뮬레이션 결과를 나타낸다. 10 에피소드마다 해당 경로를 저장하여 나타낸 결과이다. Fig. 5(b)는 10번째 에피소드의 경로를 나타낸다. 처음 시작 지점을 조금 벗어난 후 갑자기 고도 3,000 m까지 발산하는 모습을 보였다. 전혀 방향성이 없이 10번째 에피소드는 종료되었다. Fig. 5(c)의 20번째 에피소드는 더욱 나빠진 결과를 보였다. 시작 지점에서 갑자기 고도를 낮추더니 지형과 부딪혀 조기에 에피소드가 끝나는 상황이 벌어졌다. 하지만, 모델이 초기에 경험할 수 있는 최악의 시나리오를 대부분 경험하고 데이터로 축적되어 30번째 에피소드부터는 타겟 포인트 방향으로 움직이는 경향을 보이기 시작한다. Fig. 5(d)에서는 산악 지형에 부딪혀 스토리가 종료되었지만, Fig. 5(e)에서 산악 지형을 피하기 위해 학습하는 모습을 보인다. 이처럼 가로, 세로 움직임으로는 비교적 빠르게 학습하였지만, Fig. 5(f)와 같이 100번째 에피소드를 지나도 산악 지형을 완전히 벗어나는 움직임을 관찰할 수 없었다. 고도 높이를 높여 장애물을 피하는 것과 가로, 세로 움직임으로 피하는 시도가 지속적으로 이루어진다. 이후 Fig. 5(g)에서와 같이 높이, 가로, 세로 방향을 적절히 섞어 산악지형을 피하는 움직임으로 이어졌다. 최종적으로 170번째 에피소드인 Fig. 5(h)에서와 같이 적절한 경로를 따라 산악지형을 통과하고 목표지점의 좌표까지 도달한 모습을 확인할 수 있었다.
DRL을 활용하여 3차원 움직임 최적화가 가능함을 증명한 사례이다. 현재의 연구는 단일 지점만을 학습하였지만, 시뮬레이션의 종류를 증가시켜 다양한 지형을 학습시키고 추후 GPS 좌표를 활용한다면 목표 도로포장이 있는 지점까지 드론이 자동으로 주행하는 결과로 이어질 수 있다.
본 연구는 학습의 난이도를 도로포장이 아닌, 산악지형으로 설정하여 보다 난이도를 높여 진행하였다. 앞으로 필요한 추후 연구는 실제로 도로인프라가 설치된 지점에서의 학습 시뮬레이션이며, 이 시뮬레이션을 탑재한 드론이 실제 자율비행에서 얼마나 효율을 발휘하는지 검증하는 연구가 추가적으로 필요하다. 즉, 멀티모달을 활용한 방식으로 접근하여 기술을 고도화해야 한다. 이미지인식과 더불어, 판단까지 할 수 있는 강화학습을 연계하여 보다 고차원의 아스팔트 포장 관리 시스템을 구축할 수 있는 기반 연구가 필요하다.
4. 결 론
본 연구는 DRL을 활용하여 드론의 비행 경로 및 고도 최적화를 시뮬레이션으로 구현한 사례를 제시하였다. 기존의 도로포장 관리 연구가 주로 영상 기반 손상 탐지에 집중된 반면, 본 연구는 드론의 자율비행 경로 최적화라는 새로운 영역을 탐구하였다.
1. 시뮬레이션 결과, 초기 학습 단계에서는 불안정한 경로와 잦은 충돌이 발생하였으나, 약 170 에피소드 이후에는 산악지형을 회피하며 목표 지점까지 도달하는 최적의 경로를 학습할 수 있었다. 이는 DRL이 복잡한 3차원 환경에서도 효과적으로 적용될 수 있음을 보여준다.
2. 본 연구는 실제 드론을 활용하지 않고 시뮬레이션 기반으로 수행되었기 때문에, 향후 연구에서는 실제 도로 인프라가 설치된 환경에서의 학습 및 검증이 필요하다. 또한 다양한 지형과 기상 조건을 반영한 시뮬레이션을 통해 모델의 일반화 성능을 강화할 필요가 있다.
3. 결론적으로, DRL 기반 드론 경로 최적화는 도로포장 관리 자동화의 핵심 기술로 발전할 잠재력이 있으며, 향후 실제 자율비행 검증을 통해 건설 및 유지관리 분야에서의 활용 가능성을 높일 수 있을 것이다.
4. 추후 도시기반 데이터가 포함된 BIM과 연동하여 고속도로, 일반도로 등을 포함하는 도심지형에서의 시뮬레이션에 대한 연구가 추후 수행되어야 할 것으로 판단된다. 사전 실증 드론 운행 전, 충분한 시뮬레이션을 거쳐 안전한 검증을 위한 단계로 반드시 추후 연구로 필요하다.
