

1. 서 론
2. 연구방법
2.1 장단기기억신경망 LSTM 및 경사하강법을 활용한 최적화
2.2 데이터 수집
2.3 학습 및 테스트
3. 결과 및 고찰
3.1 학습 결과
3.2 테스트 결과
4. 결 론
1. 서 론
아스팔트 도로포장의 가장 근본적인 파괴 원인은 차량의 유동이다. 차량 유동이 적은 지역의 아스팔트 포장은 도심의 아스팔트 포장보다 유지보수 건수가 적다(한국건설기술연구원, 2022). 아스팔트 포장 자체의 물리적인 사용량이 적기 때문으로 해석할 수 있다. 물론, 아스팔트 포장의 열화 및 파괴의 원인으로 물리적인 사용량 외에도 환경적 요소, 제설에 의한 염화칼슘의 사용 등 외부적 요인이 다양하게 작용한다(강민수, 2012). 하지만, 가장 큰 원인은 바로 직접적인 아스팔트 포장의 사용에서 비롯된다. 차량이 진행하면서 발생하는 마찰에 의한 하중, 차량 무게에 의한 하중 등이 반복적으로 아스팔트 포장에 가력된다. 무엇보다, 반복적인 하중은 재료에 반드시 피로를 유도하게 된다. 아스팔트는 점도가 높은 유체를 활용하여 억지로 골재들을 잡아두는 역할을 한다. 설치 후 일정 시간이 지나면서 굳어지는 스티프닝으로 포장이 경도를 확보하지만, 바인더의 스티프닝으로 인한 특성 변화로 균열과 박락에 취약하다(김종호 등, 2006).
서울은 유동인구와 차량 통행이 타 지역에 비해 비교할 수 없이 많다. 인구집중 현상으로 서울시내에 많은 인구가 몰려 있기 때문이다(박제인 등, 2006). 더불어, 서울시내 건축물과 인프라시설의 노후화가 가속화되면서 재건축이 시행되고 있는 실정이다(서울 열린데이터 광장, 2024). 재건축으로 인하여 하중이 높은 차량인 레미콘, 덤프 등의 유동이 늘어나면서 아스팔트 포장의 수명 단축이 우려된다.
아스팔트 포장 파괴는 해당 지역의 교통량과 관련이 있다고 가정할 수 있다. 실제로, 교통량과 포장의 사용수명은 교통량에 따라 사용수명이 급격히 줄어듦을 확인한 사례가 있다(Kim et al., 2015). 따라서, 교통량을 추정하는 것으로 아스팔트 포장의 수명을 추정할 수 있다. 하지만, 포장의 수명을 추정하기에 앞서, 정확한 교통량의 추정에 대한 작업이 이루어져야 한다. 한 지역의 교통량을 추정하는 연구는 쉽게 찾아볼 수 있다. Oh et al.(2023)은 LightGBM 모델을 활용하여 교통량 추정 연구를 수행하였다. LightGBM은 결정트리 기반의 모델이며, 일종의 앙상블 계열의 머신러닝이다(Ke et al., 2017). 앙상블 기법은 베이지안 통계 기술 중 하나로(Zeng et al., 2023), LightGBM은 일종의 베이즈 통계 기반 머신러닝으로 분류할 수 있다. Oh et al.(2023)의 연구는 국내 정부 오픈API에서 데이터를 제공받아 지점ID, 교통량, 도로의 분류 등 다양한 파라미터를 적용하여 교통량 추정에 성공하였다. 비슷한 통계 머신러닝으로 Berlotti et al.(2024) 등의 연구가 있으며, 사용된 방법론 또한 비슷하다. Seo and Kim(2020)은 도로 CCTV영상 데이터를 기반으로 딥러닝 활용 교통량 추정을 실시하였다. 영상데이터를 활용한다는 측면에서 가장 직관적이지만, 영역이 다소 좁을 수 있다는 단점이 존재한다.
소개된 연구들은 모두 직관적으로 교통량을 추정할 수 있는 방법론을 제시한다. 하지만, 교통량은 일부 기상조건에 영향을 받는다는 보고가 있다(Lu et al., 2018). 교통량과 직접적인 데이터를 활용한 추정 연구는 비교적 높은 수준의 예측 정확도를 보인다(Ke et al., 2017; Seo and Kim, 2020; Oh et al., 2023; Zeng et al., 2023). 하지만, 교통량과 관련이 있지만 그 연관도가 떨어지는 기상데이터를 활용하여 교통량을 추정하는 연구는 쉽게 찾아볼 수 없다. 이러한 간접데이터를 활용하게 되면 예측 정확도는 크게 떨어지며, 경향성을 맞추기도 어려워진다. 하지만, 역으로 생각해보면, 기존 연구들과 같이 Test 단계에서 그래프를 매우 타이트하게 예측한다고 가정하면, 오히려 타이트하게 맞는 예측은 교통량의 불확실성을 다소 반영하지 못한다는 단점이 존재한다. 예를 들어, 2020년 5월의 A 지역의 교통량이 2021년 5월과 같을 수 없으며, 마찬가지로, 2024년 5월의 교통량이 2025년 5월과 같을 수 없다. 즉, 변동성을 고려한다면 범위 내 예측이 필요하다. 하지만, 대부분의 기존 연구는 타이트한 Fitting에 초점을 두고 있으며, 교통량 추정을 환경적 요인으로 추정한 사례가 극히 드물다. 본 연구에서는 특정 지역의 교통량이 인구유동 및 날씨에 영향을 받는다는 가정 하에, 순환신경망의 일종인 장단기기억신경망(Long-Short Term Memory, LSTM)을 활용하여 교통량 추정을 연구하였다. 타 연구와 같은 fitting이 아닌, 범위 내 추정으로 정확도를 평가하였으며, 활용 데이터는 기상 데이터의 기온, 상대습도, 일조량과 인구유동 데이터인 최대인구유동 및 최소인구유동값을 인풋 데이터로 활용하였으며, 도출값은 교통량으로 설정하였다.
2. 연구방법
2.1 장단기기억신경망 LSTM 및 경사하강법을 활용한 최적화
LSTM은 시계열 데이터를 학습시키고 추정하는데 탁월한 모델이다. 본 연구에서 활용한 데이터는 모두 시계열 데이터로, LSTM의 적용은 적합하다 판단할 수 있다. LSTM은 순환신경망의 일종으로, 기존의 순환신경망보다 더욱 복잡한 구조를 가지고 있다. Fig. 1은 LSTM의 구조를 나타낸 모식도이다.
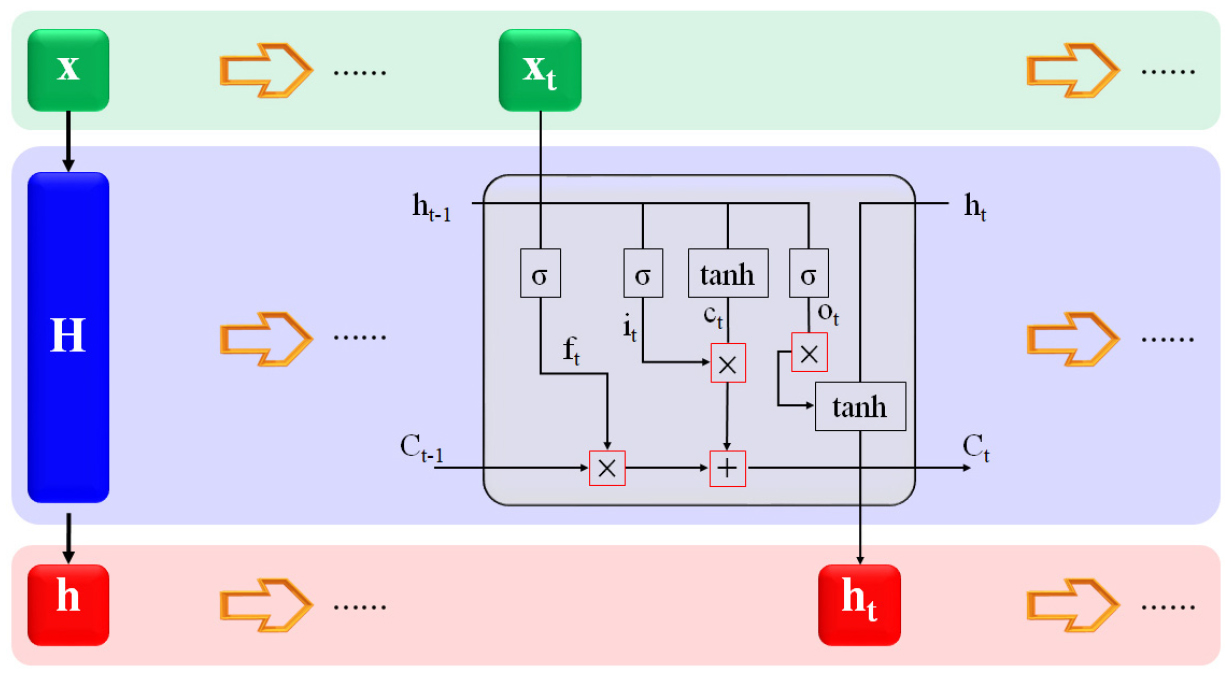
Fig. 1에서 은닉층(H)의 내부구조를 cell로 명명한다. 여기서, 순환신경망의 가장 기초모델은 cell 내부의 활성화 함수가 1개 적용된다. 하지만, LSTM은 cell의 개수가 증가하고 각각의 역할이 주어져있다. Sigmoid 및 tanh 활성화 함수들이 행렬곱 및 행렬합산의 복잡한 연산을 거쳐 출력값을 도출한다. Fig. 1에서 각각의 셀로 전파될 때, 의 함수를 따라 전파된다. 각 cell 전파 함수는 식 (1)에서 (6)까지 나타낼 수 있다.
여기서, 는 각 함수에 적용된 가중치이이고, 는 시그모이드 함수, 는 파라볼릭탄젠트 함수이다. 위의 Fig. 1 및 식 (1)-(6)은 순전파 메커니즘을 보여주며, 역전파는 각 식이 미분된 형태로 적용되고, 최종적으로 각 위치에서의 가중치를 갱신한다.
단순히 LSTM의 순전파 및 역전파를 적용하게 되면, 학습 효율이 떨어질 수 있다. 즉, 가중치가 발산할 수 있다. 이러한 현상을 방지하기 위해서 필요한 것이 최적화이며, 본 연구에서는 LSTM에서 가장 많이 활용되는 경사하강법을 적용하였다. 식 (7)은 경사하강법의 메커니즘을 보여준다.
경사하강법은 결국 가장 최적화된 값의 를 찾는 작업이다. 식 (7)에서 는 업데이트 된 파라미터 값, 는 현재의 파라미터 값, 는 손실함수 에 대한 기울기, 는 통상적으로 머신러닝의 학습률로 통용된다. 또한, 손실함수는 가장 기본적인 2차 방정식을 적용하였다.
2.2 데이터 수집
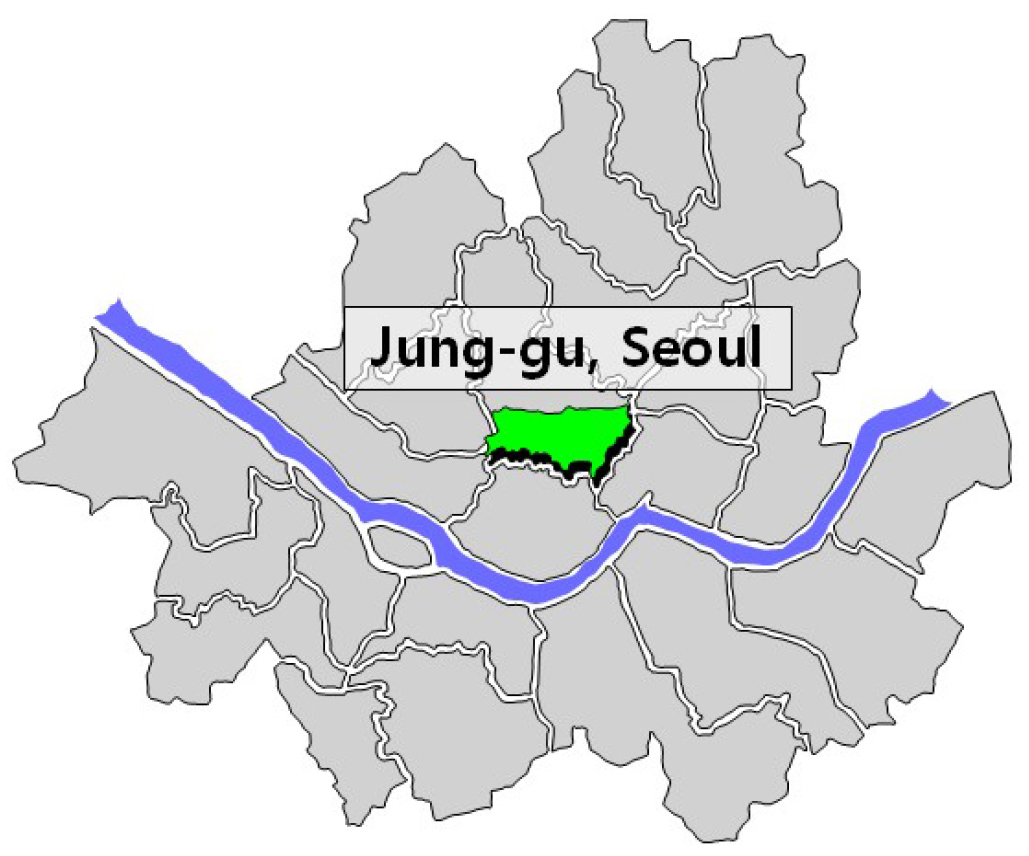
데이터의 수집은 일단위 데이터를 활용하였다. 교통량의 경우, 서울시 중구를 목표로 잡았으며, 서울시 중구의 교통량 데이터에서 유출 및 유입은 고려하지 않았다. 유출 및 유입 모두 유동량으로 간주하여 합산하여 서울시 중구의 교통량을 처리하였다. 교통량 데이터는 서울시 교통량 데이터 오픈 API를 활용하여 수집하였으며(Seoul City, 2024), 서울시 인구 유동 데이터는 최대 유동인구와 최저 유동인구를 활용하였다(Open Data Center of Seoul City, 2024). 기후 데이터는 평균 기온(°C), 평균 상대습도(%), 일조량(MJ/m2)을 활용하였으며, 기상청의 오픈 API를 통해 일별 단위로 데이터를 수집하였다(Open Portal of Weather Data, 2024). 수집된 데이터는 2020년도 01월 01일 부터 2024년도 10월 31일까지의 데이터를 활용하였다. Table 1은 데이터 구성의 예시이며, Fig. 2는 타겟 지역이다. Table 1에서 사용된 파라미터는 Input에 Date 및 Traffics를 제외한 나머지를, Output에는 Traffics가 들어간다. 즉, Date는 주요 인자가 아니며, 5대1 대응의 Input-output 구조를 가진다.
입력 파라미터는 기온, 상대습도, 일조량, 최대인구유동, 최소인구유동이며, 출력 파라미터는 교통량이다. 데이터 스케일을 맞추기 위해 인구유동과 교통량 데이터는 1000단위로 설정하였다.
Table 1.
Example of data structure in this study.
| Date |
Temperature- Average |
RH- Average |
Sunlight- Average |
Max people flow (10 k) |
Min People flow (10 k) |
Traffics (10 k) |
| 2020.01.01 | -2.2 | 64.4 | 4.53 | 52 | 22 | 64 |
| ⋮ | ||||||
| 2024.10.31 | 15.9 | 67.8 | 5.37 | 32 | 23 | 80 |
2.3 학습 및 테스트
일반적으로, 학습 및 테스트는 시계열 데이터, 이미지 데이터 활용 기계학습에서 80%는 학습으로, 20%는 테스트로 활용한다(Jang et al., 2024). 하지만, 본 연구에서는 2024년도에 수집된 데이터 모두를 테스트 데이터로 두고, 그 외 2020년부터 2023년도의 데이터는 모두 학습 데이터로 활용하였다. 학습 환경은 그래픽카드를 활용하지 않아도 충분한 속도가 보장되므로, 일반적인 컴퓨팅 환경에서 진행되었다. Table 2는 본 연구에 적용된 파라미터 값이다.
3. 결과 및 고찰
3.1 학습 결과
Fig. 3은 학습과정에서 발생한 손실 그래프이다. 초기 30 epoch까지는 손실이 0.49 부근에서 머물러 있다가, 이후 급격하게 감소하는 경향을 볼 수 있다. 경사하강법에서 볼 수 있는 특징으로, 최적화 과정에서 발생하는 초기 에러로 볼 수 있다. 하지만, 학습이 점점 원활하게 진행되면서 점점 손실이 줄어드는 경향을 볼 수 있다. 이는 일반적인 기계학습에서 흔히 발견되는 추세로, 학습은 원활하게 이루어졌다는 것을 확인할 수 있다(Woo et al., 2024).
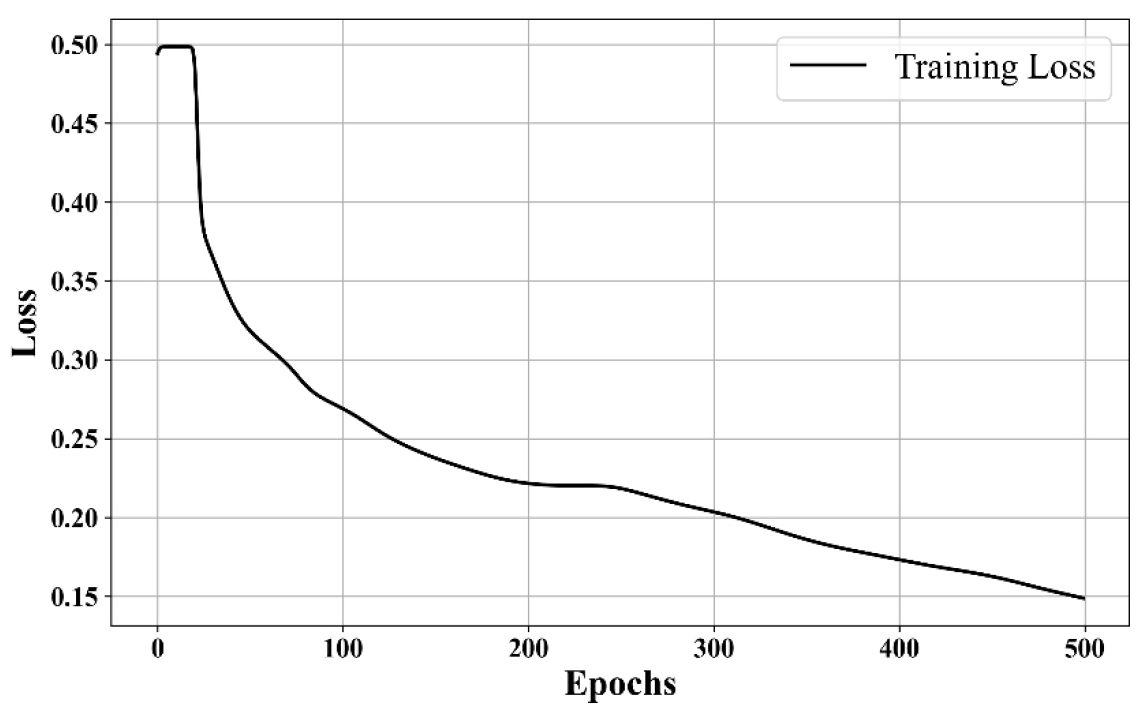
이미지 분류계열의 기계학습에서는 반드시 그래픽카드를 활용한다. 또한, 그 학습 속도가 충분히 확보될 수 없는 부분이 종종 발생하기 때문에 보통 Epoch의 수가 적절히 타협된다. 적게는 10에서 30 정도로(Huang et al., 2020), 일반적으로는 100에서 200정도로 설정하게 된다(Woo et al., 2024). 하지만, 본 연구에서는 500으로 설정되었는데, 이는 시계열 데이터 활용 기계학습에서 가장 흔하게 볼 수 있는 수치이다(Lee and Yang, 2023). 이유는, 그래픽카드 없이도 충분한 학습속도가 보장되며, 시계열 데이터의 특성 상 데이터의 고저가 자유롭다. 따라서, 복잡한 페턴을 학습하게 되기 때문에, 효율적인 결과를 얻기 위해서 높은 수의 epoch를 종종 적용한다. 학습 결과는 일반적인 기계학습 수준으로 잘 이루어진 것으로 판단된다.
3.2 테스트 결과
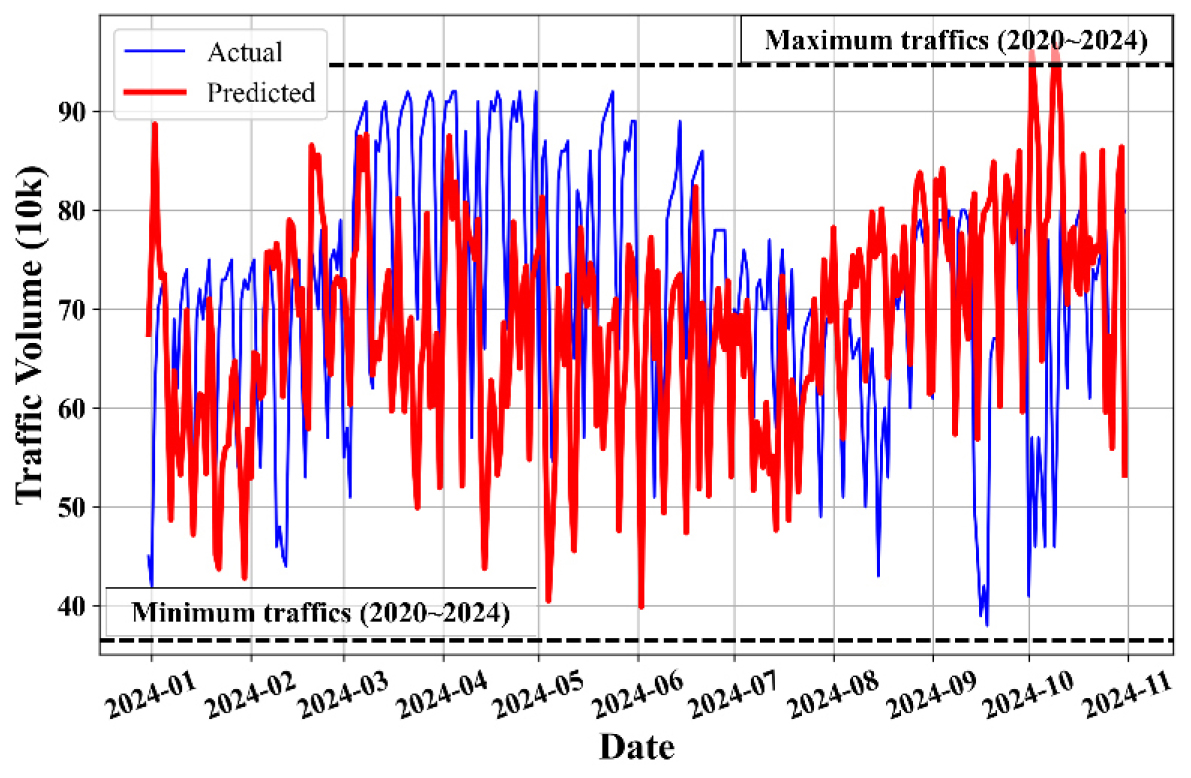
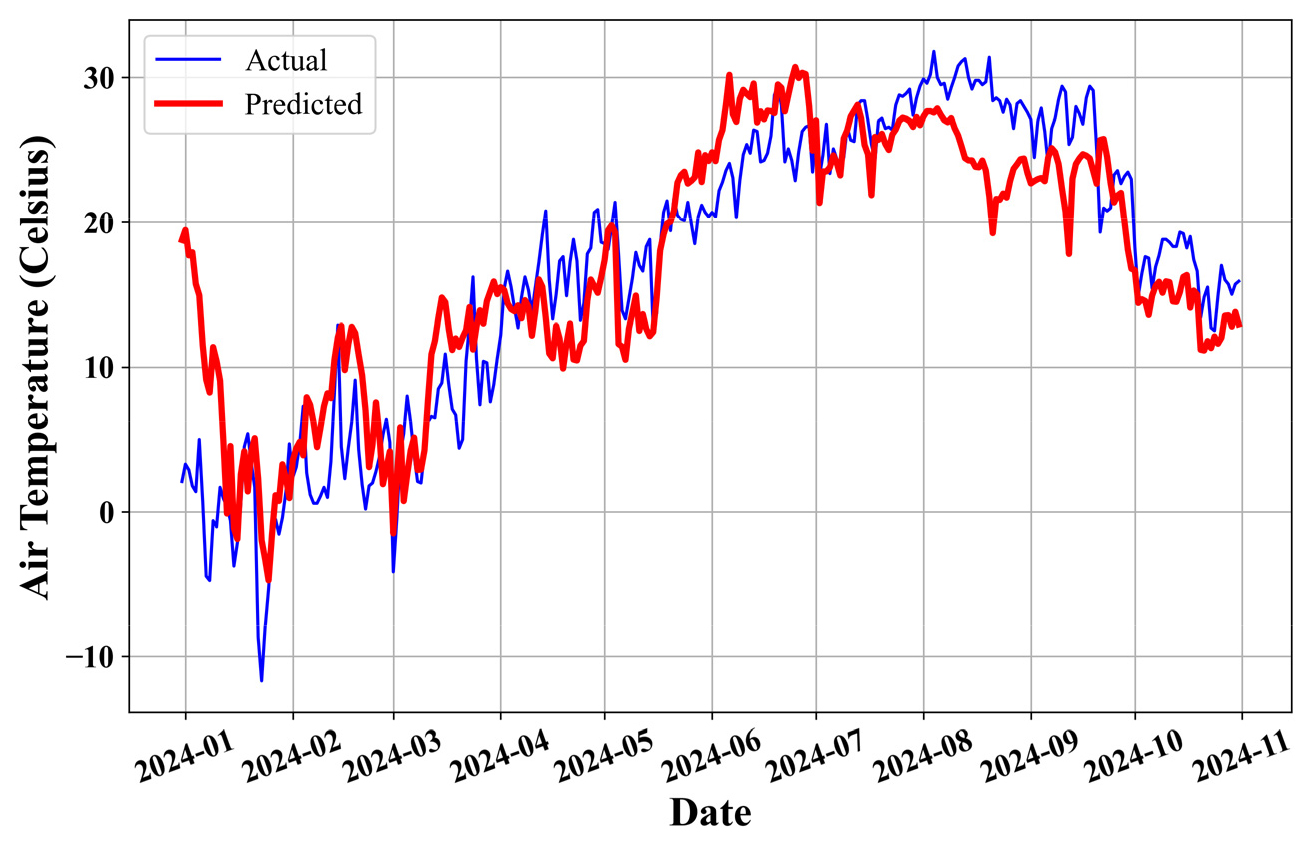
Fig. 4는 테스트 결과이다. 앞서 언급한 바와 같이, 간접적인 관계를 가지는 데이터를 활용하여 높은 수준의 추정은 불가능하다. 예를들어, Fig. 5와 같이, 기상데이터만을 활용하여 기온을 추정하는 기계학습을 수행한다고 가정해보자. 일조량, 상대습도의 2가지 파라미터만으로도 Fig. 5와 같은 높은 수준의 추정이 가능하다. 즉, 더욱 정확한 예측이 가능하다는 것으로 해석할 수 있다. 하지만, 교통량과 기상데이터, 유동인구는 간접적인 영향요소이나, 최대/최소 범위 내에서 알맞게 예측이 가능함을 확인할 수 있었다. 직접적인 데이터를 함께 사용한다면 Fig. 5와 같은 높은 품질의 예측이 가능할 것으로 판단된다. 하지만, 교통량은 언제나 그 유동이 불확실하기 때문에, 범위 내에서 예측된 Fig. 4의 결과 또한 충분히 활용 가능한 것으로 판단할 수 있다. 즉, 2020년도에서 2024년도의 교통량 최대-최소값을 비교하였을 때, LSTM에서 추정한 최대-최소값은 충분히 범위내에 들어온다는 것이다. 또한, 일부 부분은 실제 데이터의 최대-최소값의 범위를 이탈하는 모습을 보이지만, 서울시내 교통량을 고려할 때, 충분히 발생할 수 있는 범위로 판단되므로, 해당 예측은 충분히 활용가능한 것으로 사료된다.
4. 결 론
본 연구에서는 인구유동, 기상데이터를 활용한 서울시 중구의 교통량 추정에 대한 방향으로 LSTM의 적용성을 연구하였다. 교통량과 인구유동 데이터 및 기상데이터는 간접적으로 영향관계가 있음을 사전 연구를 통해 알 수 있다. 하지만, 이러한 간접데이터 및 인공신경망을 활용하여 교통량을 추정한 사례는 극히 드물다. 하지만, 본 연구에서는 간접데이터를 활용하더라도 충분히 교통량 추정이 가능함을 입증하였다.
1. 한정된 지역에서의 데이터를 활용하였지만, 시계열 데이터의 추정으로써 LSTM이 충분한 성능을 보일 수 있음을 확인하였다. 학습과정에서의 손실에서 그 결과를 명확하게 확인할 수 있었다.
2. 본 연구에서는 Fig. 5와 같은 높은 품질의 예측 결과보다 최대/최소 범위 내로 추정값이 분포하는 것을 성공의 여부로 판단하였다. 간접적인 관계를 가지는 데이터를 활용하여 높은 수준의 추정은 기대할 수 없으나, Fig. 4와 같이 범위내로 추정이 가능함을 확인하였다.
3. 테스트 결과에서 교통량의 증감 경향은 잘 반영된 것으로 판단된다. 또한, 외적 변수로 인한 불확실성을 고려할 때, LSTM을 활용한 교통량 추정은 충분히 의미 있는 결과로 도출된 것으로 판단된다.
