

1. 서 론
인공지능(Artificial Intelligence, AI)의 기술이 발전하면서 이미지 혹은 영상 데이터 기반 추정 기술이 크게 발달하고 있다. 신경망 모델의 경량화는 매년 빠른 속도로 진행되고 있다. 여기에는 다양한 신경망들이 포함될 수 있다. 예를 들어, 경량합성곱신경망(Lightweight Convolutional Neural Network, Lightweight CNN), 스파이크신경망(Spiking Neural Network, SNN), 그리고 이진화신경망(Binary Neural Network, BNN) 등이 있다.
아스팔트 포장에서 포트홀(Pothole)은 차량 이용자에게 가장 치명적인 포장 결함이다. 포트홀의 깊이가 깊을수록 타이어 손상이 심각해지며, 타이어손상을 피하더라도 차량이 방향성을 잃고 미끄러지거나 전복될 수 있다 (우병훈 등, 2024). 재료적인 메커니즘(Mechanism)을 따져보면 포트홀의 생성은 피할 수 없다. 아스팔트 바인더를 고온에서 녹여 골재 주변으로 코팅이 되도록 유도하고, 녹은 바인더는 액체상태에서 서로 연결된 고리를 형성한다. 이후, 천천히 식어가면서 1차 경화가 일어나고, 자외선과 산소에 의한 산화과정으로 2차 경화가 발생한다. 여기서, 경화 후 아스팔트는 반복하중에 의해 내부 균열이 발생하며, 서로 연결성을 잃고 결국 박리가 천천히 발생한다(Luo et al., 2023). 가장 중요한 것은 포트홀의 범위가 넓어지고 깊이가 깊어지기 전에 미리 손상부위를 파악하여 신속한 대응을 하는 것이 중요하다. 이와 관련한 부분으로 많은 연구들이 진행되어왔다.
보통의 이미지 학습의 특징은 라벨링(Labeling)이 필수적이다. 라벨링은 이미지 내부에서 학습하고자 하는 특정 부위에 클래스(Class)-좌표-바운딩박스(Bounding box)의 크기 등을 지정하는 것을 일컫는다. 특히, 포트홀과 같이 다발적으로 생성되는 결함의 경우, 다객체인식이 중요하여, 미리 포트홀의 클래스(객체의 종류 판단 코드를 부여), 이미지 상의 좌표, 바운딩박스의 크기 정보를 담아둔다(Prakash and Velampalli, 2021). 이렇게 라벨링된 이미지와 함께 신경망 학습을 실시하게 되며, 신경망 학습 시 바운딩박스 내부의 특징을 인식하도록 한다. 특히, 이미지 분류에 사용되는 신경망은 여전히 CNN 기반 모델들이 대부분이며, 심층 CNN 구조를 활용하는 사례가 많다. 대표적으로, 심층 CNN 중 가장 활발하게 활용되는 U-net의 경우, 객체 탐지 성능이 매우 우수한 것을 단적으로 확인할 수 있다(Zhang et al., 2024). 심층 구조로 성능은 우수하지만, CNN 기반의 심층 모델들은 전력소비가 크다는 것이다. Lightweight CNN의 경우도 연산량이 많아서, 그래픽카드의 병렬연산법을 활용하여 속도를 크게 높여야 한다. 하지만, 그래픽카드의 병렬연산의 효율 극대화에도 U-net이나 타 심층 CNN 모델들은 1학습 당 30초 이상의 혹은 180초 이상의 학습 시간을 보이게 된다. 또한, 그래픽카드에 부하율이 급격하게 증가하게 되어 사용 수명이 극단적으로 짧아지는 단점이 존재한다.
이러한 이유로 경량화 연구가 주목을 받고 있는 것이다. 포트홀 탐지 연구는 특히 라벨링이 이미지 당 여러 영역에 존재하기 때문에, 학습에 대한 인식은 경량 모델에 대한 신뢰도가 높지 못하다. 하지만, 우병훈 등(2024)의 사례와 같이 긍정적인 결과를 기대할 수 있는 연구도 존재한다. 경량화에 대한 연구는 오히려 CNN을 사용하지 않고 장단기기억신경망 혹은 순환신경망과 같은 이미지 분류에서는 잘 사용되지 않는 신경망을 활용한 사례가 존재한다(Moser et al., 2023). 이미지 데이터도 픽셀(Pixel) 값에 따라 색이 다르게 구현되는 것으로 본다면, 분명히 이미지 데이터도 숫자로 활용할 수 있다. 이러한 측면에서 볼 때, 포트홀 탐지도 충분히 가능하다.
본 연구는 이러한 경량화 연구의 일환으로 CNN 기반 아키텍쳐를 선택하지 않고, 인공신경망(Artificial Neural Network, ANN)에 기반한 접근을 시도하였다. 이미 라벨링이 된 이미지 영역에 대해서 바운딩박스 외의 구간을 1/10의 픽셀값으로 모두 낮추고, ANN이 학습해야 할 영역의 값은 원본 상태로 보존하여 선택적 데이터 강조를 통한 학습을 시도하였다. CNN의 기본 원리는 보통 3 × 3 혹은 2 × 2 행렬크기의 커널(Kernel)을 이미지에 적용하여 특징을 합성곱에 의해 수치화한 피쳐맵(Feature map)을 통하여 이미지를 학습한다. 하지만 ANN은 완전히 다른 방식으로 학습하는데, 활성화함수와 은닉층 내부에서 데이터값을 가중치와 함께 연산학습하여 그 값을 도출한다. 따라서, 앞서 언급한 바와 같이 특징을 잡아내기 위하여 바운딩박스 외의 구간을 모두 선택적으로 값을 낮춘 것이다. 이러한 방식을 통하여 본 연구에 대한 신경망 학습을 실시하였다.
2. 연구방법
2.1 데이터 수집 및 학습 환경
학습은 기계학습의 성능을 끌어내기 위한 가장 중요한 재료이다. 아스팔트 포장의 포트홀에 대한 이미지는 콘크리트 균열 이미지 데이터보다 그 수요가 적기 때문에, 사실상 15,000장 이상의 확보는 매우 어렵다. 모든 오픈소스를 활용하여 종합하여도, 중복되는 데이터가 상당하기 때문에, 순정 데이터만으로는 일정량 이상 데이터의 확보가 힘들다. 포트홀은 여러 영역에 다발적으로 발생하는 경우가 많으므로, 지도학습을 실시하고자 한다면 수작업으로 라벨링이 필요하기 때문에 데이터 소스를 제작하는 것도 난이도가 높다. 하지만, Roboflow 오픈소스에서는 일정량 이상 양질의 데이터가 확보되어 있기 때문에, 해당 소스에서 제공되는 포트홀 학습용 이미지를 확보하였다(Atikur Rahman Chitholian, 2020). 학습에 467개의 이미지, 검증용 이미지가 133개로 준비되어있다. 학습용 이미지는 비교적 포트홀의 특징이 명확한 이미지들로 구성되어, 학습 시 난이도가 낮은 부류의 이미지를 일컫는다. 검증용 이미지는 포트홀 외에, 다른 사물들이 함께 잡혀있어 포트홀만을 잡아내는데 방해가 되는 요소들이 함께 공존하는 난이도가 높은 이미지를 일컫는다.
Table 1은 본 연구에 활용된 컴퓨터의 사양을 나타낸다. 이미지 분류에는 아무리 모델이 가볍더라도 그래픽처리단위(Graphic Processing Unit, GPU)의 활용이 필요하다. 하지만, GPU가 필요한 상황임에도 GPU를 사용할 수 없다면, Google에서 개발한 Colab을 활용할 수 있다. Colab은 Google의 클라우드에 기반하여 기계학습을 수행할 수 있으며, 코드 또한 파이썬(Python) 기반으로 활용이 가능하여, Colab 환경에서 분석을 실시하였다.
Table 1.
Computer specification
| Core | GPU | Memory | Environment |
|
Intel i5-14400F (10 cores, maximum 4.70 GHz speed) | None |
DDR5 16 GB RAM (2.8 GHz speed) | Colab - Google |
이미지데이터는 모두 64 × 64로 크기를 재변환하였으며, 실제 크기는 64 × 64 × 3이다. 여기서, 3은 RGB의 채널수를 일컬으며, 모든 학습은 컬러스케일을 반영하였다. 배치크기는 64, 학습률은 0.001, epoch는 100, 최적화 함수는 torch 라이브러리에서 제공하는 Adam을 활용하였다.
2.2 학습 프로세스
기존의 CNN 모델의 학습방식과는 다른 접근법을 활용한다. 우병훈 등(2024)의 연구에서 이미지 데이터값을 평탄화 하면 학습의 효율이 향상됨을 확인하였다. 이러한 원리를 응용하고, 오픈소스에서 제공되는 데이터의 라벨링 특성을 활용하여 바운딩박스 밖의 영역은 약하게 인식되도록 유도한다. 전체 프로세스는 Fig. 1과 같다.
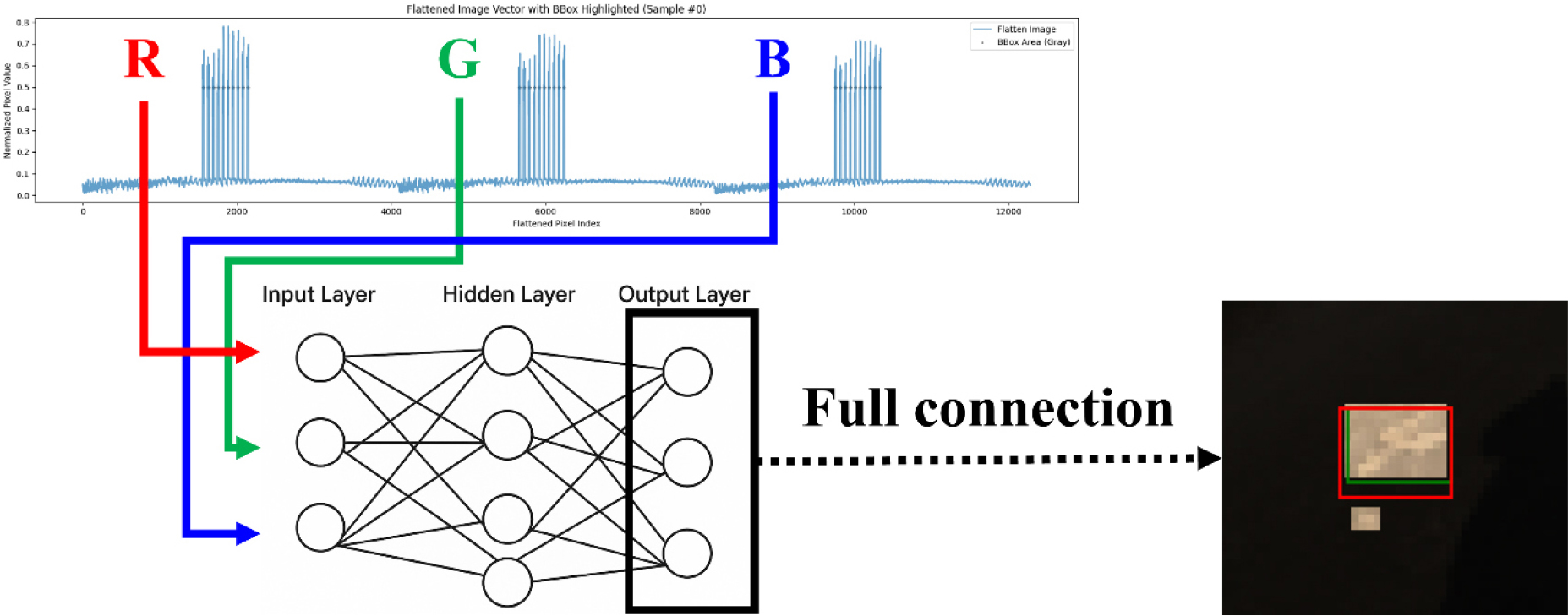
Fig. 1에서 ANN은 순전파-은닉층-역전파의 가장 기본적인 구조를 통하여 학습을 진행한다. 특히, output layer에서 각각 흩어져있는 RGB 데이터를 모두 하나로 다시 융합하는 full connection 방식은 CNN의 fully connected 방식과 같다. 활성화 함수는 분류형 학습에 최적화된 ReLu를 적용하였다. 학습 시 입력 데이터는 Fig. 1과 같이 이미지를 Red 채널, Green 채널, Blue 채널로 쪼갠 후 평탄화 하였다. 또한, 바운딩박스 바깥 영역의 데이터 값이 크게 줄어있는 것을 확인할 수 있다. 이로 인하여 바운딩 박스 내부의 데이터만 강조되어 특징을 학습하는데 큰 도움이 된다. 최종 컬러스케일의 예측된 영역을 표시하고 빨간색 바운딩박스로 표시하도록 아키텍쳐를 구성하였다. 오픈소스에서 제공한 바운딩박스는 Ground Truth (GT)로 원래의 영역을 나타낸다. 위의 프로세스에서 핵심은 ANN의 가벼운 구조를 통하여 이미지의 객체 탐지이므로, 위의 프로세스에 대한 가능성을 평가하는 것이 가장 주된 목표이다.
학습에 대한 내용은 CNN이 보다 효율적이라고 판단할 수 있겠지만, 병렬연산처리가 불가능한 상황이라면, 본 연구의 방식을 차용하여 접근이 가능하다. CNN과 본 연구에서 활용한 ANN 이미지 학습의 차이는 아래 Table 2에 정리하였다.
Table 2.
Difference between CNN and ANN
| CNN | ANN |
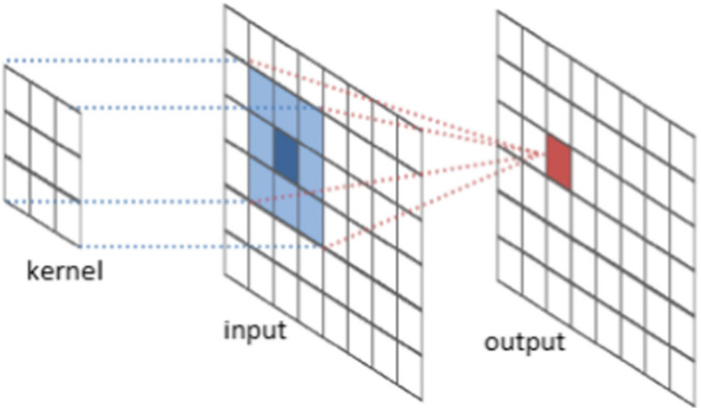 (Prakash and Velampalli, 2021) |  |
| Kernel moving and convolution values from the filters | Input the numeric data to input layers and calculation from hidden layers |
| Heavy, but precise | Light, but less precise |
Table 2의 비교와 같이, CNN보다 정밀한 결과를 기대할 수 없지만, ANN을 활용한 이미지 분류기술 또한 충분히 적용 가치가 있는 가벼운 방식이라 할 수 있다.
3. 결과 및 고찰
3.1 학습 결과
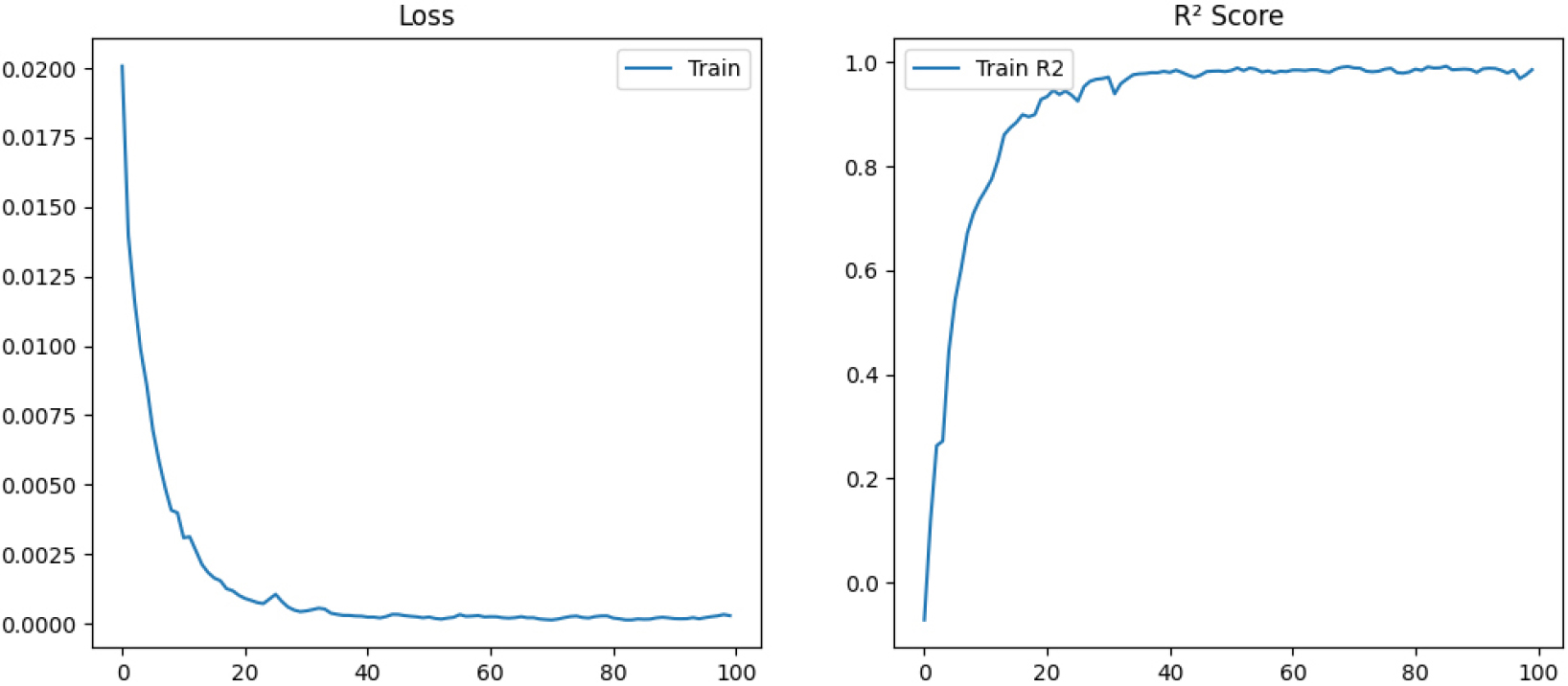
Fig. 2는 본 학습 아키텍쳐에 대한 손실 및 학습 R2 평가에 대한 결과이다. R2 값은 보통 신뢰도를 평가하는 척도로 활용된다. 학습 손실은 전형적으로 안정적인 학습이 이루어졌음을 보인다. 손실이 0으로 수렴함에 있어, 그 완만함과 이후 학습이 안정적으로 수렴하는 부분에서 가장 정석적인 결과로 평가할 수 있다. 학습 과정에서 추적한 R2 값은 Intersection over union(IoU)에 대한 심층적인 부분을 담을 수 없었다. 따라서, 학습과정에서의 포트홀 유무에 대하여 탐지되었음과 미탐지에 대한 바이너리값을 바탕으로 도출된 결과이다. 즉, 손실과 R2의 경향으로는 학습 자체가 잘 이루어졌음을 알 수 있다. 하지만, IoU와 같은 심층적인 값을 도출할 수는 없었다. 모델의 성능은 Test 단계에서 평가하여야 한다.
3.2 테스트 결과
Table 3은 테스트 결과를 종합한 표이다. 테스트 단계에서 모델의 성능이 명확하게 드러났다. 양호하게 포트홀을 탐지한 결과에서는 탐지 영역과 GT 영역의 차이가 크게 차이나지 않는다. Table 3의 well detected 케이스의 2번째 경우가 대표적인데, 이러한 영역 차이는 IoU 값이 0.6338로 충분히 유효한 탐지값이다. IoU는 0.5 이상의 값인 경우 양호한 객체 탐지로 인식평가하고 0.75 이상인 경우 모델의 객체 탐지 성능이 매우 우수함을 나타낸다(Barnhart et al., 2022). 모델의 Test 전체 평가에 대한 IoU는 0.5373으로 양호한 정도로 평가된다. 하지만, 문제는 저조한 수준의 디텍션의 사례에서 드러난다. Table 3의 Poorly detected 케이스의 공통적인 특징은 GT와 예측 영역의 겹침 구간이 매우 작다는 것이며, 심지어는 예측 영역이 GT의 밖에서 잡히는 경우도 있다.


손실, R2에서 학습단계에서 가려진 허수에 대한 부분이 여기서 드러난다. 예측 영역이 GT 밖으로 나가있는 경우는 탐지로 인정될 수 없다. 하지만, 학습과정에서의 평가는 탐지/미탐지로 평가되어 손실과 R2 값을 평가하기 때문에 이러한 허수를 걸러내는 것이 무엇보다 중요하다. ANN을 통한 포트홀 탐지는 종합적인 IoU 값은 0.5 이상을 보여 무난한 성능을 나타낸다. 하지만, 결과를 보면, 양호한 탐지 케이스와 불량 탐지 케이스의 예측 바운딩박스는 극단적으로 나뉜다. 포트홀이 명확함에도 불량 탐지가 발생하는 경우로 보아, 그림자 혹은 노면의 상태에 따라 영향을 받은 것으로 사료된다. CNN 베이스의 모델이 지속적인 발전을 거듭하여 위와 같은 저조한 결과의 빈도가 낮다. 하지만, ANN은 학습 시 관련 데이터를 함께 학습하였기 때문에, 변화에 취약한 것으로 나타났다. 이러한 부분은 보완되어야 한다.
이 결과를 바탕으로 두 가지를 종합할 수 있다. 첫 번째는 이미지를 수치데이터화 하여 ANN과 같은 모델에 적용하는 것이 가능하며, 일정 수준 이상의 이미지 탐지 성능을 보일 수 있음을 입증하였다. 두 번째는 Poorly detected 케이스와 같은 허수 영역을 학습 수준에서 걸러낼 수 있도록 학습아키텍쳐를 고안하여야 한다는 점이다. CNN과 같은 무거운 모델을 활용할 수 없을 경우, ANN으로 충분히 대체가 가능한 것을 확인하였으므로, 아키텍쳐 연구를 더욱 진행하여 허수영역을 걸러내고 더욱 신뢰도가 높은 손실 및 R2 값을 얻어내는 것이 중요하다는 것이다.
4. 결 론
본 연구에서는 ANN 아키텍쳐를 활용하여 포트홀 객체 분류가 가능하다는 것을 입증하였다. CNN의 아키텍쳐를 빌리지 않고, 단순한 이미지 전처리로 ANN에 적합한 데이터구조를 확립 후 학습을 통하여 결과를 도출하였다. 이로 인하여 파생된 종합적인 결론은 아래와 같다:
1) 손실과 R2 값을 볼 때, 학습 자체는 안정적으로 이루어진 것으로 판단된다. 하지만, Table 3의 poorly detected 케이스에서 학습과정에서 손실과 R2 평가에 허수가 적용된 것을 확인하였다.
2) 이 외에, 양호한 탐지 케이스에서는 대부분 높은 수준의 영역 겹침을 보여주었고, 이 모델이 제대로 연구가 된다면 충분히 CNN을 활용하지 않아도 객체 분류 탐지가 가능할 것으로 판단된다.
3) 전체적인 IoU값은 0.5373으로 양호하지만, 국제적인 경쟁력을 갖추려면 0.75 이상을 달성해야 한다. 이를 달성하기 위해서는 학습과정에서 허수를 걸러냄과 동시에 양호한 loss 및 R2 값을 확보해야 한다. 이 부분은 아키텍쳐 연구의 영역이므로, 추후 연구로 발전가능성을 시사할 것이다.
4) 추후 연구에서 활용 가능한 신경망은 심층신경망 혹은 순환신경망을 활용할 수 있다. 심층신경망 및 순환신경망 외에도 베이지안신경망과 같은 통계를 기반으로 하여 작동하는 신경망을 활용할 수도 있다. 따라서, 본 연구의 확장으로 성능을 고도화하고 다양한 시도를 통하여 이미지 분류 연구에 단일 신경망(주로 CNN)에 집중되는 현상을 완화할 수 있을 것으로 기대한다.
