

1. 서 론
포트홀(pothole)은 수직깊이 150 mm 이상 움푹 패인 일종의 구덩이 형태의 도로포장체 결함을 일컫는다(Woo et al., 2024). 포트홀이 발생하는 주요 원인은 다양한데, 과적 차량의 과도한 하중, 이상기후에 의한 설계 강우량보다 많은 강우량, 기층의 손상 등 다양한 원인으로 인하여 아스팔트 포장이 손상되며, 이 과정에서 포트홀이 발생한다(Lee et al., 2023). 수직깊이 150 mm는 차량의 타이어 및 휠의 손상과 심한 경우, 차량 프레임까지 손상을 유발할 수 있다(Ali et al., 2023). 또한, 포트홀은 차량 주행 방향에 영향을 줄 수 있으며, 차량의 제어를 순간 놓치게 만들어 큰 사고로 이어질 수 있다(Ali et al., 2023). 국제적으로 포트홀의 예방과 사후관리는 필수적인 사항이며, 재료적으로 성능을 향상시켜 예방하거나, 이미 발생할 사항에 대하여 탐지의 정확도를 높여 사후관리를 용이하게 하는 방식으로 진행되고 있다(Woo et al., 2024). 특히, 유지관리 측면에서 포트홀의 탐지 정확도를 높이기 위한 방안으로 스마트 기술이 다수 적용되고 있다(Woo et al., 2024). 포트홀의 경우, 센서를 활용한 진동, 수축, 팽창 등 수치적으로 얻어지는 시계열 데이터(Jang et al., 2024)가 아니라, 이미지 베이스의 데이터이다. 시계열 데이터 혹은 수치 데이터의 경우, 상대적으로 이미지 데이터보다 처리 및 학습이 용이하며, 예측 결과도 매우 높은 편이다(Woo et al., 2022; Jang et al., 2024). 하지만, 이미지 기반 기계학습의 경우, 다양한 노이즈와 특정 타겟에 대한 학습이 필요하다. 따라서, 상대적으로 수치/시계열 데이터를 활용한 기계학습보다 난이도가 높다. 그래픽카드(Graphic Processing Unit, GPU) 환경에서 학습이 가능해지기 시작하면서 빠른 이미지 학습을 통해 본격적으로 다양한 이미지 베이스 연구가 태동하였다(Zhong et al., 2018). 이러한 연구의 한 방향으로 포트홀 탐지 또한 현재까지도 활발하게 연구되는 주제이다(Egaji et al., 2021). 기계학습 베이스에서 가장 기본이 되는 인공신경망은 합성곱 인공신경망(Convolutional Neural Network, CNN)이 가장 대표적이다. Nhat-Duc et al.(2018)은 아스팔트 균열에서 균열이 가지고 있는 가장자리가 가지는 형태학적 특성에 집중하였다. 즉, edge-detection을 활용하여 아스팔트의 균열을 탐지하는 것이 목표로, 이 연구에는 CNN이 활용되었다. 결과는 Nhat-Duc et al.(2018)의 연구방법으로 83.33 %의 정확도로 도로포장의 균열을 탐지하는 결과를 보였다. 또 다른 예로, Ye et al.(2021) 또한 CNN을 활용하였다. 다만, 앞서 언급한 연구와 다른 부분은, pre-pooling을 적용하여 CNN의 활용성을 높였다는 점이다. Ye et al.(2021)의 포트홀 탐지 결과는 98% 이상의 값을 보였는데, 이 연구에 사용된 이미지 데이터세트 자체가 난이도가 높지 않았다. 포트홀만 특징적으로 잡혀 있었으며, 테스트 세트에서도 노이즈는 극히 드물었다. 이러한 부분이 Ye et al.(2021)의 연구의 한계점으로 보인다. 실제로, 최근에는 사용 이미지의 난이도에 따라 연구의 질이 크게 차이가 난다. 따라서, 최근 포트홀 추적 연구를 보면, 이미지에는 그림자, 나무, 자동차, 사람 등 다양하게 포트홀 탐지에 방해되는 요소가 섞여 있다. 물론, Open API를 활용한 데이터 제공처에서는 데이터 사용자에게 학습의 편의를 제공하기 위해 데이터 세트 구성을 이미지와 레이블 데이터로 같이 제공한다. 또한, CNN의 기술이 지속적으로 발전하여 심층-CNN을 주로 사용한다. 비록, 기존 CNN보다 학습 시간이 몇 배로 걸리지만(Huang et al., 2020), 그 정확도 및 이미지에 존재하는 노이즈 필터와 같은 성능에서는 기존 CNN이 따라잡을 수 없다. Hoang and Tran(2022)은 심층-CNN을 활용하여 아스팔트 포장체의 초기 박락을 탐지하는 연구를 수행하였다. 골재와 바인더의 2개 팩터가 구분사항으로, 이미지는 회색조로 처리하여 학습을 수행하였다. 박락이 시작되는 지점과 아닌 지점은 확연한 차이를 보이는데, 박락 시작영역은 골재 노출에 의하여 거친 표면을 보이며, 박락이 아닌 지점은 바인더의 영역이 많아, 상대적으로 깨끗한 표면을 보인다 (Hoang and Tran, 2022). 그 정확도는 95%를 상회하는 값을 보였다. 심층-CNN을 활용한 예시는 최근 더 많이 찾아볼 수 있다. 다른 예로, Klco et al.(2023)은 실시간 물체 탐지 시스템인 YOLOv5를 활용하여 포트홀 추적을 실시하였다. YOLO 혹은 UNet(Huang et al., 2020)과 같이 특별히 명칭된 이미지 분류 기계학습에 적용되는 모델들은 모두 심층-CNN에 기반하며, 그 구조를 연구 목적에 맞게 개량하여 적용하는 모델들이다. 즉, YOLOv5 또한 심층-CNN의 일종이며, 현재는 YOLOv11까지 성능이 향상된 모델이 활용되는 것으로 보고되었다(Sapkota et al., 2024). Klco et al.(2023)의 연구 역시 95% 이상의 높은 정확도를 보였으며, 이는 심층-CNN의 성능에서 기인함을 알 수 있다. 이와 같이, CNN기반 모델들은 현재 이미지 데이터를 활용한 기계학습에서는 가장 필수적인 신경망으로 자리잡았다. 하지만, 모든 연구에서 보이는 특징은, 데이터 처리방식이나 신경망 구조의 변화를 도모한다. 데이터의 처리 측면에서는 이미지의 회색조 변환이 있다. 특정 연구 목적에 의하여 여전히 사용되는 이미지 데이터 처리방식이다(Chen et al., 2022). 신경망 구조의 변환 측면에서는 CNN의 구조 자체를 변환하거나(Huang et al., 2020), 특정 원리를 적용한 필터층의 추가하여 기능적 측면의 변화(Xiang et al., 2022)를 도모하는 방식이 있다. 두 방식 모두 활발히 적용되는 방식이다. 하지만, 특정 필터층의 구성 및 추가는 CNN의 구조를 무겁게 만들거나, 오히려 성능을 저하시킬 수 있다. 따라서, 필터층을 고안하여 적용하는 것은 신중하게 고려되어야 한다. Spiking VGG7 모델의 경우(Xiang et al., 2022), 심층-CNN의 합성곱층에 Spiking 필터층을 추가한 사례로, 성능향상이 된 사례로 들 수 있다. 또 다른 예로, 가중치 적용 방식의 변화이다. CNN기반 모델에서 보기 드문 사례로, Bayesian-CNN (BCNN)이 있다(Zhang and Diao, 2023). 학습 진행 시 각 필터에 갱신된 사후확률분포를 가중치로써 적용하는 방식이다. BCNN은 기존의 CNN이 가지고 있던 약점들을 보완하는데, 불확실성을 반영하며, 과적합을 방지한다(Leyva et al., 2024). 특히, 적은 양의 데이터로도 학습이 가능하다는 장점이 있다(Zhang and Diao, 2023; Leyva et al., 2024). 컴퓨터비전(Leyva et al., 2024), 농업(Zhang and Diao, 2023) 등 다양한 방면으로 BCNN은 연구되고 있다. 하지만, 건설분야에서는 아직 적용사례가 드물다. Bayesian 확률론을 최적화 방식에 적용한 사례가 일부 있지만(Sun et al., 2023), RGB 컬러 스케일에서 균열이나 포트홀 추적에 BCNN을 활용한 사례는 극히 드물다. 따라서, 본 연구에서는, 컬러스케일의 이미지 학습을 통해 포트홀을 구분해내기 위한 기계학습을 실시하였다. 기계학습에는 BCNN이 주체가 되었으며, 기존 연구에서 활용하는 평가지표인 정밀도, 재현율, F1점수, 혼동행렬을 통하여 모델의 성능을 평가하였다. 본 연구를 통하여 BCNN의 활용에 대한 통찰을 제공하고자 한다.
2. 연구방법
2.1 Bayesian-CNN
BCNN은 CNN구조에 베이지안 추론 개념을 적용하여, 가중치의 불확실성을 모델링할 수 있다. BCNN은 일반적인 신경망의 가중치가 갱신되고 고정된 값으로 학습이 마무리되는 반면, BCNN은 가중치를 확률분포로 표현하여 불확실성을 반영하는 특징을 가지고 있다. 이러한 특성으로 적은 양의 데이터로도 충분한 학습이 가능하며, 노이즈가 많은 데이터에서도 안정적인 데이터 예측이 가능하다. 즉, CNN의 학습 효율 향상과 예측 정확도의 향상을 도모할 수 있다.
BCNN의 확률분포형 가중치에 대해 이해하기 위해서 먼저 베이즈추론에 대해 이해할 필요가 있다. 베이즈추론은 베이지안 확률론적 접근에서 주로 사후확률에 기반한 확률적 추론을 의미한다. 식 (1)은 베이지안 추론에서 가장 기본이 되는 원리이다(Woo et al., 2022).
여기서, 는 사후확률, 는 사전확률, 는 가능도확률 혹은 함수, 는 마지널 상수로 사실상 관계를 따지면 에 의해서 사후확률이 결정된다고 볼 수 있다(Woo et al., 2022).
위의 원리가 CNN의 합성곱층에서 가중치로서 적용이 된다. 특히, 본 연구에서는 이미지를 컬러스케일에서 학습을 시킨다. 즉, 최대한 노이즈를 효과적으로 필터링 하기 위하여 이미지를 R, G, B 채널로 분리하고 각 채널 레이어에서 이미지를 학습시켜 포트홀 추적을 더욱 효과적으로 수행하고자 접근하였다. 또한, 각 컬러 채널 별 확정되는 확률분포를 Flattening에서 합성하기 위해 따로따로 채널을 분리한 것이다. Fig. 1은 본 연구에서 적용한 BCNN의 흐름도이다.
위와 같은 구조의 BCNN을 활용하여 이미지 학습을 실시하였으며, 학습손실을 추적하여 학습이 원활하게 이루어졌는지 확인하였다.
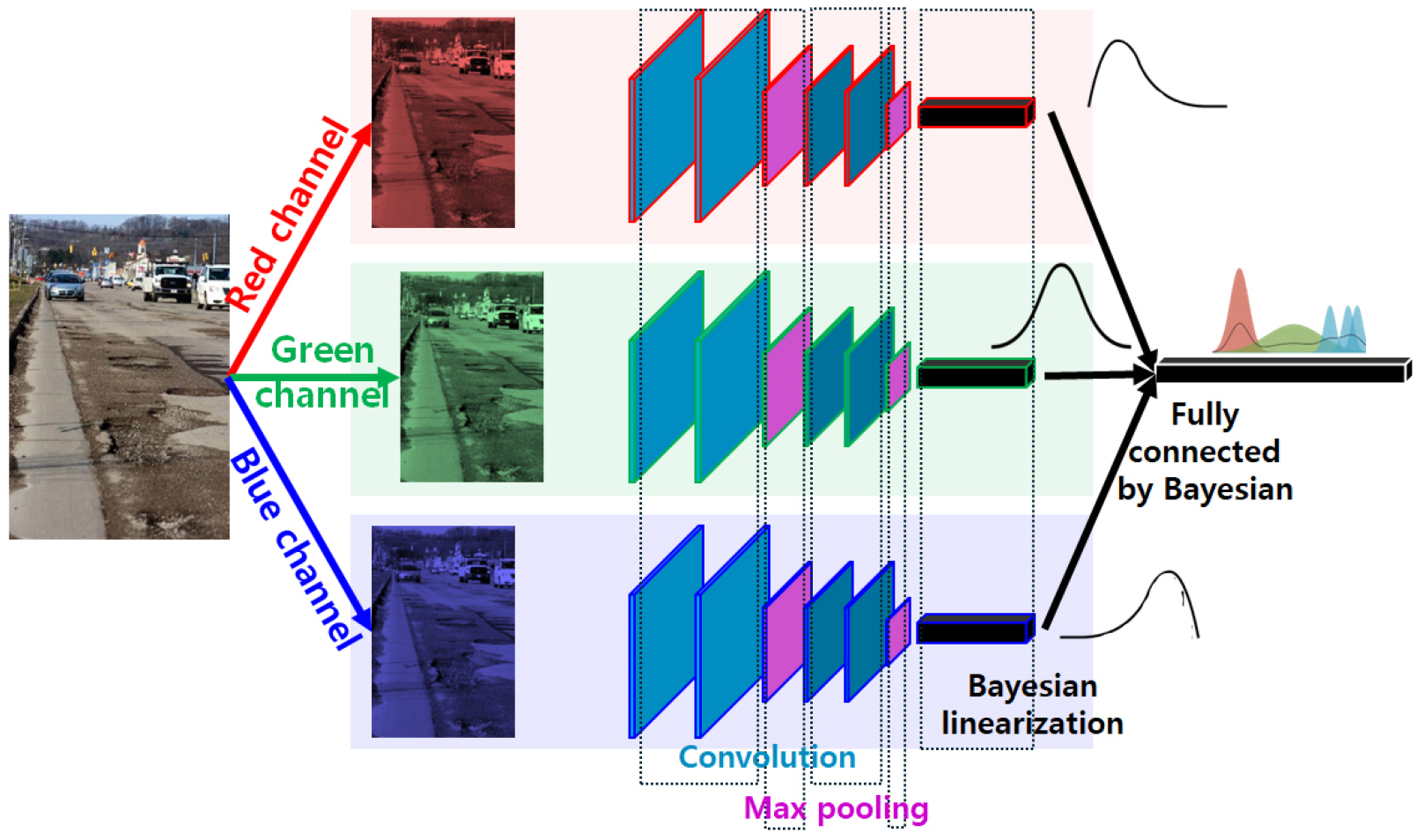
2.2 학습환경과 데이터 수집
학습에는 GPU를 활용한 CUDA 환경에서 진행되었으며, Table 1과 같은 컴퓨터 시스템에서 기계학습이 수행되었다. 또한, 학습을 위한 파이썬 코드 환경은 Table 2와 같이 설정하였다. 특히, Table 2에서 Image resize를 실시한 이유는, 입력 이미지(학습, 테스트, 검증 모두)가 가지고 있는 크기가 모두 다르기 때문에, 학습 및 모델의 효율을 위하여 일정 값으로 크기를 고정한 작업으로 설명할 수 있다.
Table 1의 환경에서 GPU가 아닌 환경에서 CNN 학습을 수행할 경우, Table 2에서와 같은 컨디션이라면 1 epoch당 1800초 이상이 소요된다. 따라서, GPU의 활용은 필수적이다. Table 2의 data scale은 픽셀값의 보정을 의미한다. Python 코드에서 이미지프로세싱을 수행하면, 출력되는 픽셀값의 범위는 0에서 255로 총 256의 범위를 가지는 큰 값의 범위로 나타내어진다. 하지만, 원활한 이미지 학습을 위해서는 0부터 1의 사이 값으로 변경해주는 것이 학습 이후 결과에 필요한 데이터를 처리하는데 있어 보다 유용하다. 학습에 사용되는 이미지들은 모두 신경망에 적용되기 전에 64 × 64 크기로 크기를 재구성한다. 효율적인 학습을 위해서 대부분의 이미지학습에서 진행하는 부분이다(Sun et al., 2023; Zhang and Diao, 2023; Leyva et al., 2024). Table 2의 학습률 값인 0.001은 기존의 이미지학습 연구에서 자주 사용되는 값이다 (Chen et al., 2022; Xiang et al., 2022; Sun et al., 2023; Zhang and Diao, 2023; Leyva et al., 2024; Sapkota et al., 2024). Padding값을 1로 설정한 이유는 3채널로 분리되어 내부 학습이 이루어지고 최종적으로 포트홀 추적을 위한 평탄화 수렴까지 원활한 진행을 위하여 1로 설정하였다.
학습환경의 설정만큼 중요한 것은 데이터의 확보이다. 본 연구에서는 이미지 기계학습에서 가장 많이 활용되는 오픈소스인 Roboflow에서 포트홀 이미지를 확보하였다(Atikur Rahman Chitholian, 2020). 학습용 포트홀 이미지 465개, 테스트용 67개, 검증용 133개의 이미지를 제공한다. 이미지의 개수가 확실히 적은 편이나, 본 연구의 BCNN은 앞서 설명한 바와 같이, 적은 데이터에서도 최적의 예측 성능을 제공할 수 있다. 이에, 이미지의 난이도는 높으나, 개수는 적은 제공자의 포트홀 이미지를 선택하였다. 이를 활용한 BCNN 포트홀 추적에 대한 기계학습을 수행하였다.
3. 결과 및 고찰
3.1 학습 결과
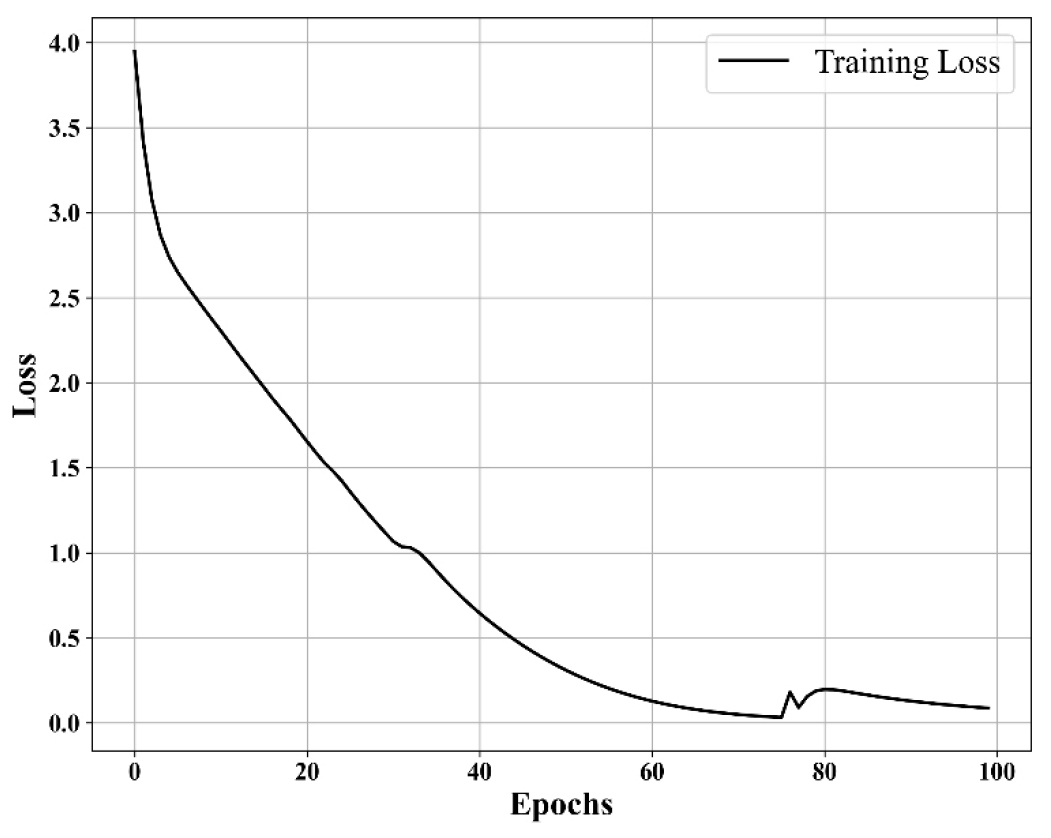
BCNN은 심층-CNN과 같은 심층구조를 가지지 않고 간단한 CNN의 구조를 가진다. 하지만, 베이지안 확률론적 방식이 가중치 갱신에 적용이 되어, Fig. 2와 같이 성공적으로 훈련이 마무리되었다.
Fig. 2에서 다른 CNN처럼 초기 20 epoch 부근에서 0에 가까워지는 경향, 즉 가파른 loss의 0으로의 수렴을 확인할 수 없었다. 하지만 100 epochs라는 충분한 반복 학습 주기를 통하여 성공적으로 0에 수렴하는 결과를 얻었다. 기존 연구에서는 보통 손실값이 초기에는 가파르게 하락하다가 향후 완만하게 하락하는 로그함수 혹은 지수함수 형태로 손실값이 하락한다(Nhat-Duc et al., 2018; Ye et al., 2021; Xiang et al., 2022). 하지만, BCNN은 불확실성이 같이 반영되며, 사후확률로 업데이트 되는 과정에서 평균과 분산 값이 최적화되는 프로세스이다(Leyva et al., 2024). 따라서 기존 연구보다는 완만한 기울기로 손실값이 하락하는 모습을 보인 것이다. 한 가지 더 특징적인 부분은, 73 epoch 시점에서 손실값이 다시 상승하고 79 epoch에서 다시 하락하는 추세를 보였다. 이 연구의 학습에서는, 적은 이미지 데이터에 대한 100 epoch의 반복 학습 과정에서 과적합이 발생할 수 있다. 그러나, 앞서 언급된 BCNN의 특징인 과적합을 방지할 수 있는 부분에서, 확률분포형태의 가중치 적용이 여기서 효과를 발휘한다. 과적합이 발생하게 되면 사후확률의 평균과 분산에서 이상이 발생하는데, 여기서 이상 예측이 발생할 수 있다(Woo et al., 2023). 이 경우, 손실값에서도 이 부분이 반영되며, 다시 최적화가 이루어지게 된다. 이러한 현상으로 73 epoch 지점에서의 손실 이상 거동이 설명될 수 있다.
3.2 포트홀 추적 결과
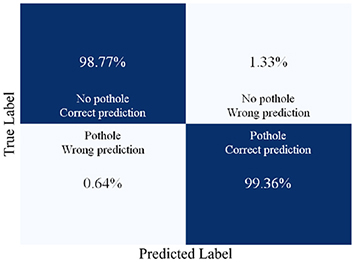
Table 3는 훈련된 모델이 추적한 포트홀 결과이다. 테스트 세트와 검증 세트에서의 결과를 보여주며, 이에 대한 정밀도, 재현율, F1점수와 혼동행렬 결과는 Table 4에 정리되어 있다.
테스트 이미지는 비교적 간단한 포트홀 이미지로 구성되어 있다. 테스트에서는 99.99%의 정밀도를 보여, 성능 스코어를 판단하는 것이 무의미 하였다. 하지만, 검증 세트의 이미지는 그림자, 차량 등 다양한 노이즈가 포함되어 있었다. 검증에서 학습된 BCNN은 99.36%의 높은 정밀도를, 98.68%의 높은 재현율을 보였다. 이는 기존 연구 중에서도 높은 성능에 속하는 수치이다(Chen et al., 2022; Xiang et al., 2022; Sapkota et al., 2024). 즉, BCNN이 검증 이미지에 대하여 99.36%의 정답을 맞추었다는 의미이며, 특히, 재현율이 98.68%라는 것은 1.32%의 낮은 수준으로 오답을 도출한다는 의미이다. 또한, 정밀도와 재현율이 아주 높은 수준의 밸런스를 이루고 있기 때문에, Table 4의 F1 score가 99.02%로 높게 도출되었다. 포트홀 추적에 있어서 다양한 노이즈가 있음에도, Table 3와 Table 4와 같이 높은 정밀도로 탐지가 가능한 것은 BCNN에서 베이지안의 원리가 충분히 CNN을 보완하여 성능을 향상시킨 것으로 판단된다.








4. 결 론
본 연구는 BCNN을 컬러스케일에서 이미지를 학습시키고 이를 활용하여 포트홀 추적의 성능을 검증하였다. 3채널로 나뉘어진 각 클래스의 컬러들은 베이지안 원리에 입각하여 확률분포화 된 각각의 가중치로써 적용되었다. 또한, BCNN의 학습 결과, 손실값이 0에 수렴하는 것을 확인하였으며, 학습이 성공적으로 이루어졌음을 확인하였다. 학습단계에서는 베이지안 확률론적 방법이 CNN에서 발생할 수 있는 과적합을 억제할 수 있는 부분이 포착되었다. 또한, 학습이 기존의 심층-CNN 혹은 CNN보다 완만하게 이루어지는 부분에서, 다른 데이터 세트가 적용된다면, epoch의 값을 조정하는 것이 필요할 것으로 판단된다. 검증부분에서는 높은 정밀도 및 재현율을 검증단계에서 보여줌으로써 충분히 BCNN을 활용한 포트홀 탐지가 가능함을 확인하였다.
향후 연구로는 YOLO 모델과 융합하여 불확실성과 함께 탐지 정확도를 높이는 방향의 연구가 필요하다. 본 연구에서 사용된 학습 및 테스트는 모두 이미지 기반이지만, 실제 적용을 위해서는 동영상 기반의 적용이 매우 중요하다. 따라서, 교차면적평가(Inersection over Union, IoU)와 함께 단순 탐지가 아닌, 영역 맞춤형 탐지를 도모한 연구가 필요하다.
