

1. 서 론
2. 이론적 배경 및 연구방법
2.1 단안깊이추정
2.2 활용 라이브러리
2.3 테스트 이미지 수집 및 연구수행 환경
3. 단안깊이추정 결과 및 고찰
3.1 정밀 추정 결과
3.2 추정 실패 케이스
4. 결 론
1. 서 론
인공지능(Artificial Intelligence, AI)의 기술이 발전하면서 이미지/영상을 활용한 객체 탐지 기술이 빠르게 발전하고 있다. 아키텍쳐의 경량화는 이미 전 세계적으로 수준급에 도달하여 있으며, 현재는 객체탐지 모델은 온라인에서 직접 파이썬으로 불러와 활용하는 시대에 이르렀으며, 실제로도 활발히 활용되고 있다(Swain and Tripathy, 2024). 모든 자원을 동원해 새로운 아키텍쳐를 고안하는 1세대 연구는 구글의 MobileNet 아키텍쳐(Howard et al., 2017)의 등장 이후로 급격하게 감소하였다. 이후, 2세대 연구는 기존에 개발된 훌륭한 아키텍쳐들을 활용하여 얼마나 실제 상황에 활용이 가능한지 검증에 가까운 연구들이 급속하게 증가하였고, 현재도 증가중이다(이경배 등, 2024). 3세대 연구는 멀티모달(Multimodal)로, 학습된 AI모델들을 조합하여 활용하는 단계로 나아갔다. 그 결과, 로보틱스(엄태영 등, 2020), 드론 자율비행(한유라・신복균, 203), 자동차 자율주행(서민수 등, 2018) 등 다양한 분야에서 그 성능을 증명하고 있다.
AI 기술의 조합으로 다양한 산업에서 생산성이 증가하고 산업이 급속도로 발전하기 때문에 모든 분야에서 AI 멀티모달에 관한 연구를 수행중이다. 건설분야도 건설 로보틱스 관련 멀티모달 연구(Liu et al., 2024), 시공현장 작업자 안전을 위한 행동 분석 멀티모달(Chen et al., 2025)과 같은 다양한 방식으로 적용중이다, 특히, 작업자 안전과 같은 부분은 객체 탐지가 필수인데, 객체 탐지는 인프라구조물의 손상 탐지 부분에서 이미 활발하게 연구가 되었다. 관련 연구의 가장 초창기에는 단순 CNN(Convolutional Neural Network)을 활용하여 손상의 유무를 판단했던 수준에서(Li and Zhao, 2019) 차츰 실시간 연구로 진화하였고(Chaiyasarn et al., 2022), 최근에는 손상의 깊이 데이터를 직접 측정하여 학습한 후 3차원 재구성에 도전하는 연구까지 수행되었다(Dow et al., 2024). 이처럼, 손상 탐지 분야도 가파른 속도로 기술이 발전되고 있다.
Dow et al.(2024)이 수행한 손상의 3차원 재구성 연구의 단점으로 깊이에 대한 정보, 즉, 촬영지점-손상부위의 각 목표지점에 대한 거리를 직접 학습시켰다는 점이다. 하지만, 기존에 개발된 기술 중 단안깊이추정(Monocular Depth Estimation, MDE) 기술이 존재한다(단안은 1개의 고정시점으로 이해할 수 있다). MDE는 AI가 이미지를 인식하고 그 이미지 내부의 깊이감을 상대적으로 표현하고 데이터화하는 기술을 말한다. Dow et al.(2024)과 같이 직접 절대값에 대한 데이터를 학습시키면 AI모델을 통해 실제 깊이를 얻을 수 있는 장점이 있지만, 단점은 학습 방법이 어렵고 시간 또한 많이 소요된다. 하지만, MDE를 활용한다면 시간이 절약되고 간단하다. 단점은 상대깊이라는 점인데, 이것 또한 거리 축적만 학습시킨다면 실제거리로 치환할 수 있다.
현재 국내외로 MDE와 객체탐지의 하이브리드 연구는 활발하게 연구되고 있다. Yu and Choi(2021)은 일반적인 객체 탐지를 수행하였는데, 기존의 모델보다 MDE를 같이 활용할 경우 효율이 극대화됨을 증명하였다. Li et al.(2023)은 로봇의 자율주행 성능 극대화를 위해서, Afshar et al.(2023)은 차량의 자율주행 성능 향상을 위해서 적용하였다. 하지만, 현재 건설분야에서 해당 기술을 접목한 사례는 드물다. MDE는 현재까지 구조물의 손상 깊이 정도를 탐지하기에는 학습된 가중치가 부족한 실정이다. 심지어, MDE 모델을 직접 학습시키기 또한 난이도가 매우 높다. 그럼에도 불구하고 MDE는 객체탐지 모델과 함께 적용되면 가장 강력한 도구임에는 의심의 여지가 없다. MDE 자체 활용도 난이도가 높고, 생소한 기술이기 때문에 건설에서는 아직 보수적으로 접근하는 것으로 판단된다.
따라서, 본 연구에서는 MDE를 활용한 도로포장의 포트홀 깊이감 재현을 통하여 MDE의 적용 가능성을 판단하고 토의하고자 한다. 현존하는 가장 강력한 MDE 모듈인 Zoe.D 모듈을 활용하여 그 가능성을 조사하였다.
2. 이론적 배경 및 연구방법
2.1 단안깊이추정
앞서 언급한바와 같이, MDE는 상대적 깊이를 추정한다. Fig. 1은 그 예시로, MDE의 결과를 잘 나타내고 있다. 가까운 물체일수록 밝게, 먼 물체일수록 어둡게 표현되어 있다. 반대로 설정하여 활용할 수 있지만, 가까울수록 밝게 설정하는 것은 사람의 심리에서 비롯된다.

MDE의 물체 깊이감을 상대거리로 데이터화 한다면 이는 구조물의 손상 탐지에도 매우 유용하게 활용할 수 있는 가능성이 커진다. MDE의 원리는 Fig. 2에서와 같이 복잡한 원리로 접근하게 된다.
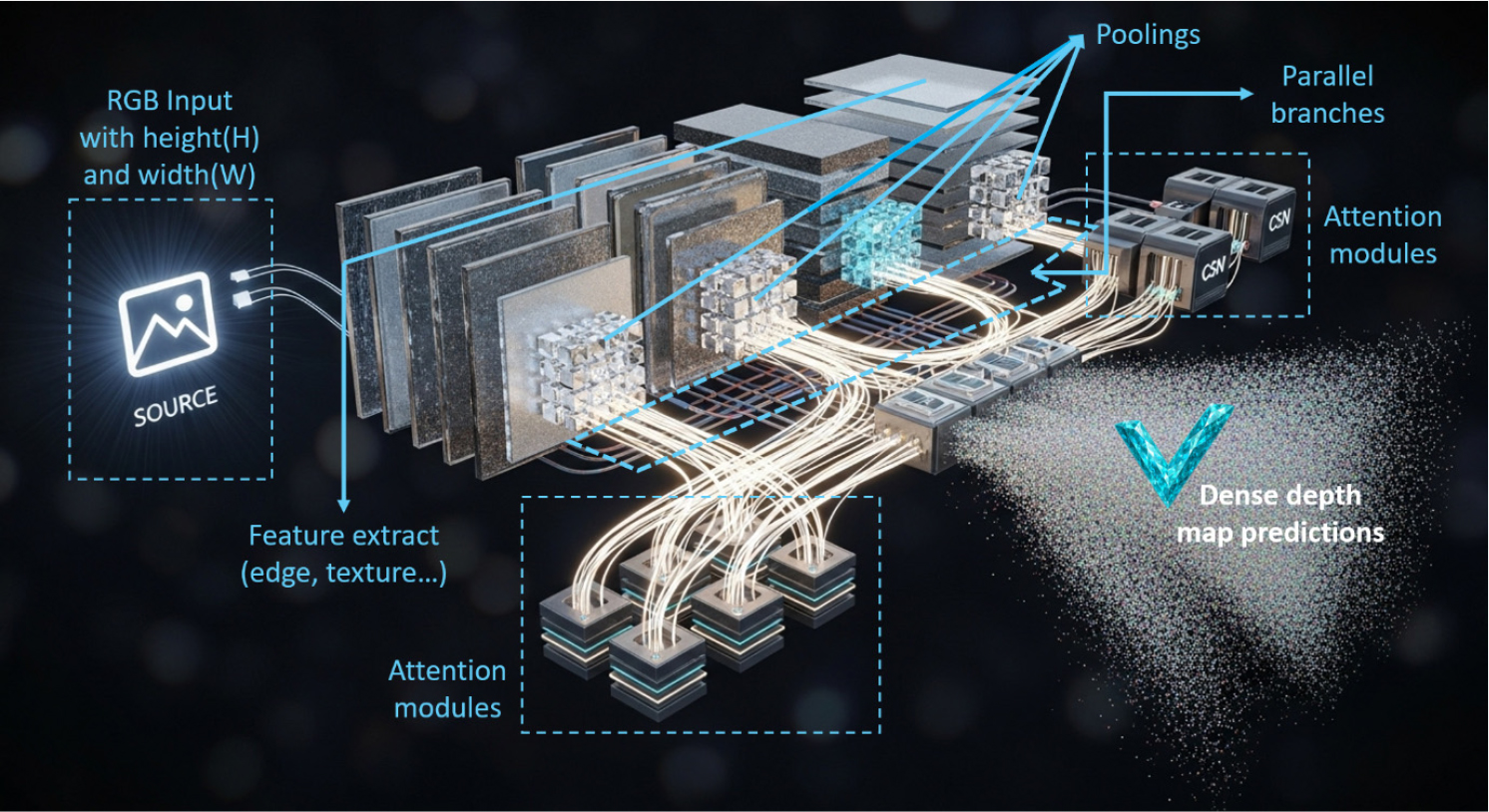
Fig. 2에서 SOURCE는 입력 이미지에 해당된다. 이미지는 총 5가지의 데이터를 제공한다. 가장 기본적인 데이터는 이미지의 크기에 해당하는 이미지 너비와 높이를 제공한다. 그리고 핵심 요소로 빨간색-초록색-파란색 채널별 픽셀 데이터(RGB)를 제공한다. 이렇게 입력된 이미지 데이터는 합성곱층으로 넘어가 특징 추출(Feature extract)을 수행하게 된다. 합성곱층에서 추출된 특징 데이터는 Pooling층을 거쳐 병렬 배치되고, Fig. 2의 Attention modules로 넘어가게 된다. 여기서, Attention은 우리가 현재 활발하게 사용하는 거대언어모델의 핵심 신경망인 Transformer에서 주축이되는 기술이다. 데이터를 토큰화 하여 정렬하고 이를 해석하는 툴로, Attention은 언어처리 외에도 이미지 데이터 객체 탐지에도 활발하게 활용되고 있다. Attention에서 토큰화되어 처리된 데이터는 최종적으로 상대 깊이 값을 예측으로 출력하여 이미지로 재구성한다. 위의 원리로 출력되는 결과가 Fig. 1과 같은 결과이다.
2.2 활용 라이브러리
본 연구는 파이썬에서 활용할 수 있는 라이브러리인 Zoe.D(Bhat et al., 2023)를 활용하였다. Zoe.D는 ZoeDepth의 약자로 MDE에서 가장 대표적인 라이브러리이다. Fig. 2에서 설명된 합성곱층은 일반적인 합성곱신경망으로 이해하면 된다. 하지만, Zoe.D 라이브러리는 인코더와 디코더 구조를 가지는데, 이는 UNet과 유사하다. 즉, 기본적인 개념의 MDE보다 Zoe.D는 더욱 강력한 추정 성능을 보이는 것이다. 또한, Zoe.D 라이브러리는 2022년도에 등록된 라이브러리로, 2022년 이전에 개발된 MDE 라이브러리의 가중치를 기본적으로 활용하고 있다.
강력한 라이브러리에도 단점은 존재한다. 거울과 같은 반사된 이미지는 인식이 어려울 가능성이 있으며, 투명한 물체에 대한 인식이 전혀 이루어지지 않는다. 이러한 부분이 구조물 손상 인식에 크게 작용할 수 있다. 포트홀을 예로 들면, 포트홀에는 물이 고여 있을 수 있으며, 이러한 부분이 노이즈로 작용하여 깊이 인식에 영향을 미칠 수 있다. 따라서, 본 연구의 포트홀 탐지를 위한 MDE 적용 가능성 조사는 큰 의미를 가진다.
2.3 테스트 이미지 수집 및 연구수행 환경
활발한 구조물 손상 탐지 연구로, 온라인에 오픈소스로 공개된 모델이 다양하게 존재한다. 공개 모델들은 학습 데이터를 함께 제공하는데, 포트홀 탐지 모델은 풍부한 학습, 테스트, 검증 이미지를 제공한다. 본 연구는 가장 풍부한 이미지 데이터세트를 제공한 소스에서 포트홀 이미지 데이터를 확보하였다(Roboflow, 2024). Zoe.D 라이브러리는 학습을 수행하지 않으며, 제공된 이미지를 직접 활용하였다.
Zoe.D 라이브러리는 고성능 병렬연산을 요구하며, Table 1과 같은 환경에서 원활하게 연구 수행이 가능하다. Table 2의 연구환경은 일반적인 기계학습 환경에서는 저성능에 해당하지만, 본 연구는 학습과정이 없기 때문에 Table 2의 환경에서도 충분히 연구 수행이 가능하였다.
3. 단안깊이추정 결과 및 고찰
아래 결과로 나타낸 Table 2와 Table 3에서 활용된 이미지는 오픈소스 활용 이미지로, 촬영 각도, 거리, 노출 정도 등의 파라미터는 무작위로 적용된다. 그럼에도 불구하고, 모듈의 포트홀 인식 여부는 매우 중요하다. 앞서 언급한, CNN 모델들과의 하이브리드 적용을 고려한다면, 이러한 사전 검토는 반드시 필요하다.
3.1 정밀 추정 결과
Table 2는 본 연구에서 수행한 포트홀 상대깊이 추정 결과를 정리한 표이다. MDE는 깊이로 표현하였지만, 상대적인 거리에 따라서 감도를 다르게 표현하기 때문에, 필요한 경우 보정을 실시하였다. Table 2 Case1의 경우, 거리감을 인식하기 매우 좋은 환경이다. 사진으로 촬영된 포트홀보다 배경의 나무가 더 멀리 있는 것으로 인식되어, 보정 전의 결과에서와 같이 배경의 나무들이 더 어두운 픽셀값을 보인다. 하지만, 보정 전 Case1의 결과에서 분명히 포트홀은 깊이가 표현되었다. 따라서, Case1은 보정처리를 실시하였다. 거리감을 제공하는 이미지의 절반까지를 모두 0으로 처리하여 거리감을 제거하였으며, 그 결과, Case1의 보정 결과와 같이 더욱 선명하게 포트홀이 나타남을 확인하였다.
Table 2.
Precise detection examples
| Case | Original image |
MDE results (before modification) |
MDE results (after modification) |
| Case1 |  | 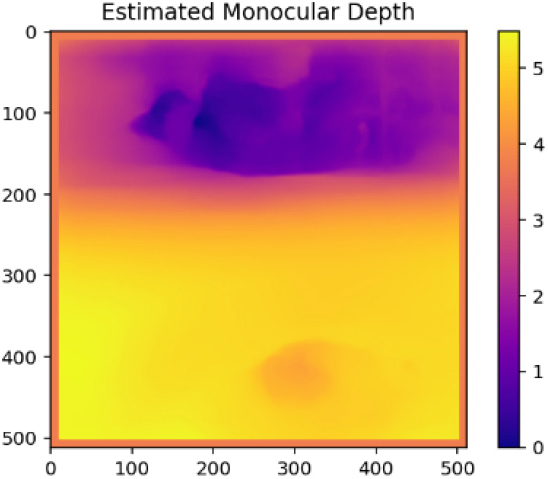 | 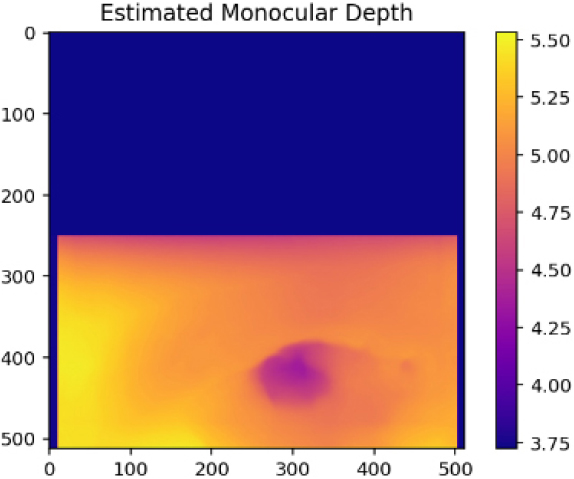 |
| Case2 |  | 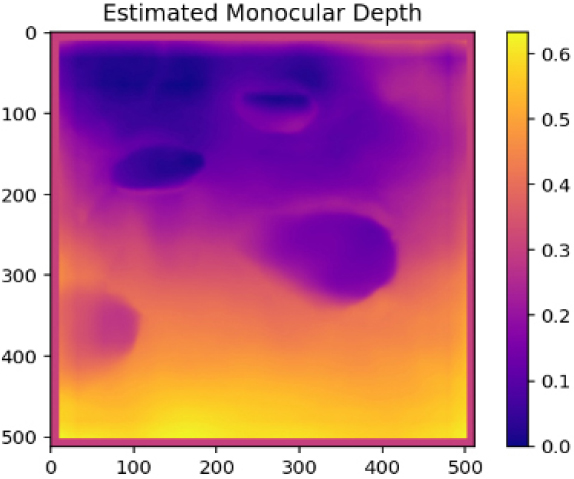 | (Without modification) |
| Case3 |  | 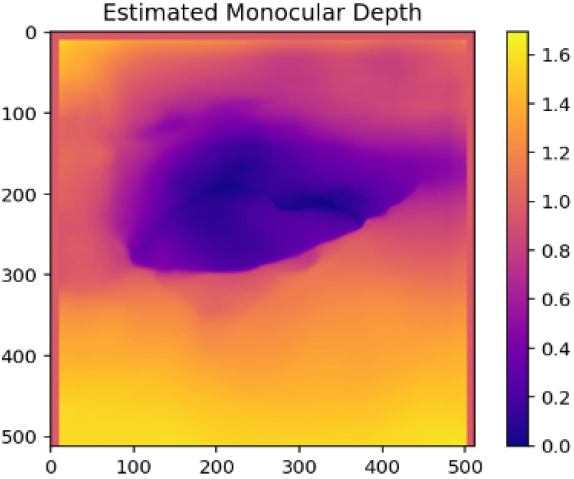 | (Without modification) |
Case2와 Case3은 가장 성공적으로 포트홀의 상대깊이가 표현된 사례이다. 두 케이스 모두 포트홀에 물이 있어 노이즈가 발생할 수 있는 데이터였다. 하지만, 촬영의 각도, 위치, 거리 등을 고려할 때, 충분히 양질의 깊이 추정을 통하여 시각화가 가능한 이미지로 판단된다. Case1의 나무와 같이 인식의 주체가 충분히 거리감을 상쇄할 수 있는 상황이라면 아무리 포트홀이 깊더라도 나무를 더욱 먼 객체로 인식하여 포트홀에 대한 깊이는 약화되어 표현될 수밖에 없다. MDE는 상대적 깊이 추정보다 이미지 내부에서 거리감에 따라 활성화되는 상대적 거리감을 활성화하는 것에 가깝기 때문이다(Huang et al., 2025). 따라서, Case2와 Case3와 같은 결과는 촬영의 위치, 주변 노이즈 객체 등이 상대적으로 적기 때문에 나타날 수 있는 양질의 결과인 것이다.
3.2 추정 실패 케이스
Table 3는 본 연구의 MDE를 활용한 포트홀 탐지(상대깊이 추정) 실패 케이스들이다. Case4의 경우 가장 먼 거리로 인식된 부분을 제거하고 최대한 포트홀이 존재하는 영역을 부각시키기 위하여 보정을 진행하였다. 하지만, 주변의 나무, 울타리, 물고임 등의 노이즈가 복합적으로 작용하여 최종적으로 탐지에 100% 실패한 케이스이다. Case5와 Case6는 보정 후 포트홀 영역이 약하게 드러나는 경향을 보였다. 노이즈가 존재하는 부분을 극단적으로 제거하여 약하게 포트홀의 깊이감이 강조된 것으로 판단된다. 하지만, Case1과 같이 뚜렷한 영역이 드러나지 않고 희미하게 영역 정도로 인식이 가능한 상태로 드러났다. 따라서, Case5와 Case6 또한 실패로 간주하였다.
Table 3.
Failure cases of depth estimation
| Case | Original image |
MDE results (before modification) |
MDE results (after modification) |
| Case4 |  | 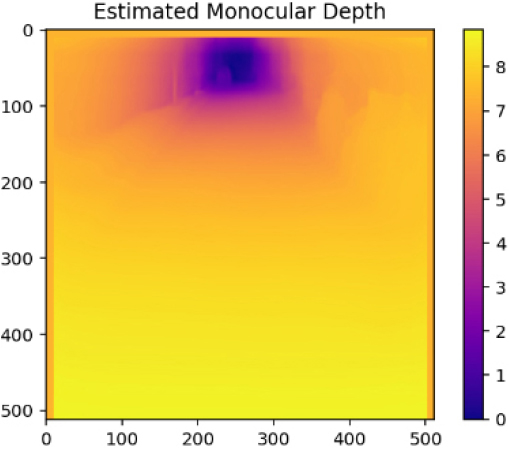 | 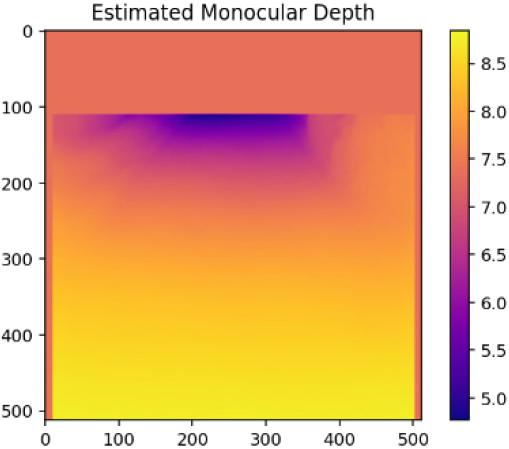 |
| Case5 |  | 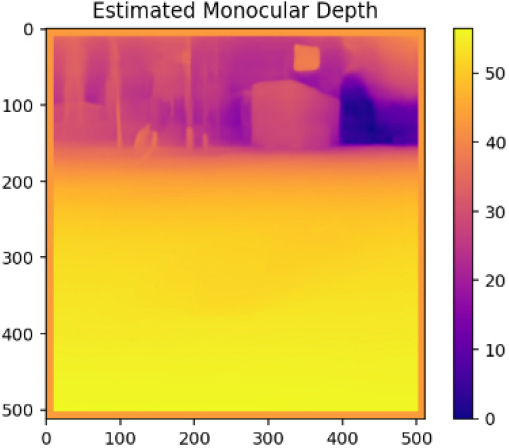 | 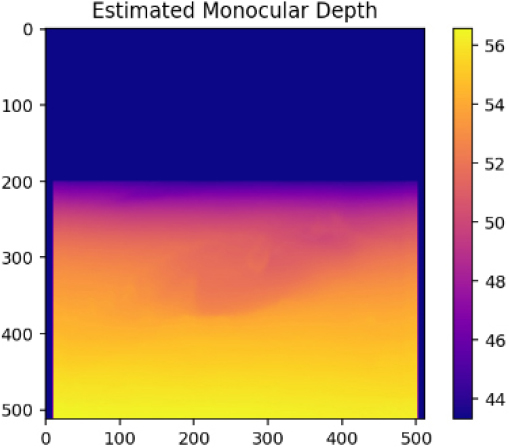 |
| Case6 |  | 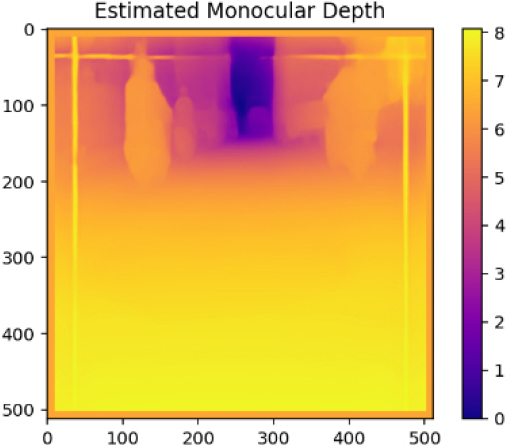 | 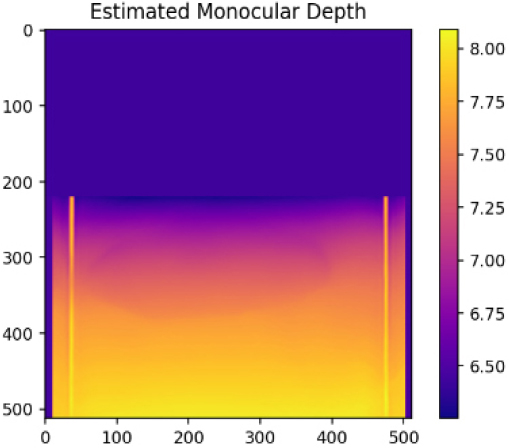 |
본 연구는 MDE를 활용하여 포트홀의 영역을 상대깊이로 표현하여 추후 멀티모달 객체탐지와 함께 활용 가능성을 판단하기 위하여 수행된 연구이다. Table 2의 Case2와 Case3와 같이 짧은 거리와 특정 높이에서 명확한 형체를 드러내는 현재의 MDE를 활용하기에는 무리가 있는 것으로 판단된다. 추후 멀티모달로써 활용하기 위한 방법에 대한 심도있는 접근이 필요할 것으로 판단된다. 본 연구에서 진행된 사례에서 확인이 가능하듯, MDE를 포트홀 탐지로의 활용이 완전히 불가능한 것은 아니다. 보정할 경우, 일부 영역으로 드러나는 사례도 확인하였고, 오히려 보정 후 영역이 뚜렷하게 나타나는 Case1과 같은 사례도 확인하였다. 따라서, MDE와 기존 객체 탐지 모델과의 융합은 충분히 고려될 수 있을 것으로 판단된다.
4. 결 론
본 연구는 MDE를 활용한 포트홀의 상대적 깊이를 시각화하고 주변 노이즈에 대해서 현재의 MDE 모델이 정확하게 포트홀을 표현하는지 검토하였다. 일관된 경향으로 포트홀 이후의 영역에 사람, 자동차, 나무, 울타리 등 더욱 멀리 있는 객체가 탐지될 경우 포트홀은 거의 나타나지 않는 문제점을 확인하였다. 하지만, MDE의 활용성에 대해 충분히 검토가 필요함을 확인하였으며, 종합적인 결론은 아래와 같다.
1. 포트홀이 가깝게 촬영된 이미지는 더욱 멀리 있는 객체, 예를들어, 나무, 자동차, 사람 등이 존재할 때, MDE는 사전 학습 가중치에서 더욱 멀리 있는 객체를 입체적으로 표현하는 경향을 확인하였다. 즉, 멀리 있는 객체가 강조되면서 포트홀의 깊이감이 표현되지 않는 치명적인 문제를 확인하였다.
2. 하지만, 일부 케이스에서 보정 후 포트홀의 윤곽이 드러나거나 깊이감이 다시 표현되는 등 보정 후 활용성에서 충분히 MDE는 멀티모달로 활용하기에 가능성이 있음을 확인하였다.
3. 기존의 객체 탐지 모델들을 따로 학습시키지 않고 포트홀을 인식시키기 위한 방안으로 MDE의 활용은 충분히 효과적일 것으로 사료된다. 복잡하게 아키텍쳐를 재구성 및 설계하지 않아도 충분히 비지도학습 계열로 계산비용을 절감할 수 있을 것으로 사료된다.
4. 본 연구는 MDE의 포트홀 적용 시 나타날 수 있는 한계를 확실히 확인한 사례이기도 하다. MDE 자체를 학습시키는 것은 매우 무거운 작업이기 때문에 추후 CNN 모델들과 함께 하이브리드로 사용할 경우, 그 효과가 충분히 높아질 것으로 기대된다. 또한, 추후 아스팔트 유지관리 차원에서 차량에 카메라를 설치하여 3차원 매핑으로 디지털트윈과 함께 사용할 경우, 2차원 이미지에서 확인하던 심각성보다 3차원으로 확인하는 포트홀의 심각성을 더욱 각인할 수 있을 것으로 기대된다.
