

1. 서 론
2. 연구방법
2.1 고령운전자의 급증
2.2 데이터 선정 및 상관관계 분석
2.3 사고심각도 산정
2.4 머신러닝 알고리즘의 선정
3. 하이퍼파라미터(Hyperparameter)를 이용한 머신러닝
4. 심각도 분석
4.1 연령별 사고 심각도 산정
4.2 사고 영향 변수 추출
5. 결 론
1. 서 론
최근, 고령 인구의 증가에 따라 도로 내 고령 운전자에 대한 사고 위험 개선 방안이 마련되고 있으나, 아직까지 고속도로에서 고령 운전자가 사고 심각도에 미치는 영향 요인에 대한 연구는 아직 미흡한 실정이다. 특히, 교통사고의 발생 원인은 단일 요인일 수도 있고 복합 요인일 수도 있으므로 사고 심각도에 영향을 미치는 다양한 인자들을 고려한 연구가 필요하다. 또한, 최근의 기후변화로 인해 예상치 못한 기후재난의 빈도와 강도가 증가하고 있는 점도 고려할 필요가 있다. 이러한 가운데, 최근 머신러닝과 딥러닝 기법의 발전으로 사고심각도를 다양한 정보를 통해 분석하는 것이 가능해졌다. Kang and Noh(2022)는 대전시를 대상으로 보행자 교통사고 심각도에 영향을 미치는 요인을 도출하고자 AdaBoost와 Random Forest 기법을 이용하였다. Kwon and Chang(2021)은 이륜자동차 교통사고 심각도에 영향을 미치는 요인을 도출하고자 XGBoost를 활용하였으며, 심각한 교통사고 예방을 위한 법규 개편방안을 제시하였다. Kim et al.(2021)은 고령 운전자에 의해 발생하는 보행자 피해 사고 심각도에 미치는 요인을 분석하고자 하였다. 이때, 로지스틱 모형과 SVM 모형이 상대적으로 높은 예측력을 보였고 정확도 측면에서는 Random Forest가 뛰어난 것으로 분석되었다. Lee and Woo(2018)는 대전광역시의 주요 교차로 중 88개 교차로를 대상으로 GRNN을 적용하여 교통사고 발생에 대한 학습을 통해 모형을 개발하였다. Son and Park(2022)는 신호교차로 접근부에서 발생하는 추돌사고의 심각도 요인을 머신러닝 기법을 사용하여 분석하였다. 머신러닝 기법을 사용하지 않았을 때와 사용한 후의 성능을 비교하였으며, 정확도와 F1-score 결과를 토대로 교통사고 심각도 분석시 머신러닝 기법 사용이 용이함을 시사하였다.
본 연구는 이상의 현 연구배경을 고려하여 관련 데이터를 수집하고 이를 머신러닝기법을 통해 사고심각도에 미치는 영향인자들을 분석하고자 한다. 이를 위해 9개의 고속도로노선에서 2014년부터 2022년까지 9년간의 데이터를 수집분석하고, 사고심각도에 미치는 영향인자들을 연령대별로 도출하고자 하였다. 영향인자 분석을 위해서 AdaBoost, XGBoost, Random Forest, SVM 네 가지 머신러닝 알고리즘을 적용하여 이를 통해 가장 적합한 알고리즘을 선정할 뿐만 아니라, 신뢰성 높은 영향인자들을 추출하고자 한다. 또한, 본 연구에서는 기후에 의한 영향에도 초점을 맞추어, 특정 기후 조건에서 어떤 사고 원인이 더 자주 발생하는지, 그리고 기후변화가 고속도로 내 교통사고 심각도에 영향을 미치는 연령대가 존재하는지도 추가적으로 분석하고자 한다.
2. 연구방법
2.1 고령운전자의 급증
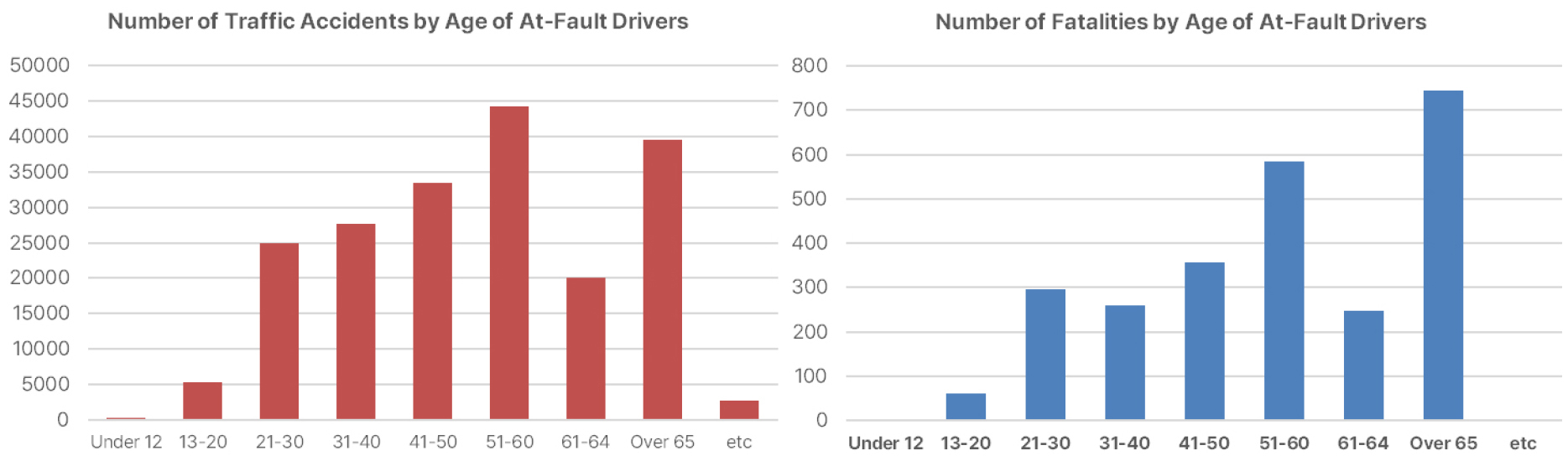
최근, 고령 운전자의 교통사고 소식이 자주 지면에 실리고 있으며, 도로교통공단(KRTA)에서 발표한 최근 3년의 통계에 의하면 고령(65세 이상) 운전자의 사고 빈도 및 발생 건수는 꾸준히 증가하고 있으며 다른 연령대에 비해 높은 수준을 보이고 있다. 가해운전자 연령층별 원인별 교통사고 통계를 보면, 사고건수와 사망자수가 동시에 증가한 연령층은 65세 이상이 유일하다. Fig. 1은 가해운전자 연령층별 사고 건수 및 부상자 수를 나타내었다.
Fig. 1을 보면, 전년도에 비해 다른 가해운전자 연령별 교통사고 사망자수는 감소하였으나 65세 이상에서는 709명에서 745명으로 5.1% 늘었다. 특히, 65세 이상에서의 사망자는 다른 연령층과 비교했을 때 최소 2배에서 8배로 고령 운전자에 대한 대책연구가 필요함을 알 수 있다.
2.2 데이터 선정 및 상관관계 분석
본 연구는 국내 고속도로 9개(경부고속도로, 광주대구고속도로, 남해고속도로, 서해안고속도로, 영동고속도로, 중부고속도로, 중부내륙고속도로, 중앙고속도로, 호남고속도로)를 선정하여 2014년부터 2022년까지 9개년의 데이터를 한국도로교통공단에서 수집하여 Table 1과 같이 정리하였다. 국내 고속도로의 경우 콘크리트와 아스팔트를 이용하여 초기 공사 및 재포장 등이 이루어지고 있으므로 명확한 구분은 하지 않았다.
Table 1의 선정한 9개 고속도로에서의 교통사고 발생건수와 연장 간의 상관관계를 파악하기 위해 상관분석을 실시하였다. 이때 사고 건수는 최근 동향을 살펴보고자 2020~2022년의 3개년의 짧은 자료를 활용하였으며 상관관계 그래프는 Fig. 2와 같으며 세부적으로 고속도로의 연장과 사망자수, 중상자수, 경상자수, 부상신고자수와의 상관관계는 Fig. 3과 같다.
Table 1.
Names and Lengths of Selected Highways
| Highway | Length (km) |
| Gyeongbu | 416.0 |
| Gwangju-Daegu | 182.0 |
| Namhae | 273.2 |
| Seohaean | 340.8 |
| Yeongdong | 234.4 |
| Jungbu | 117.2 |
| Junbu Naeryuk | 302.9 |
| Jungang | 288.9 |
| Honam | 195.2 |
우선, Fig. 2와 같이 고속도로 길이가 길어짐에 따라 사고 건수가 증가할 것이라는 회귀분포형 그래프를 도출하였다. 길이(km)와 전체 사고 건수간의 상관관계에 대한 p-value는 약 0.0361이며 이는 통계적으로 유의미한 수준을 나타낸다. 여기서, p-value는 통계적 가설검정에 가설이 맞다고 가정했을 때 관찰되는 데이터나 그보다 극단적인 데이터가 나타날 확률이다. 또한, Fig. 3에서 사망자수, 중상자수, 경상자수, 부상신고자수 4가지에 대한 상관계수 및 p-value를 정리하면 Table 2와 같다.
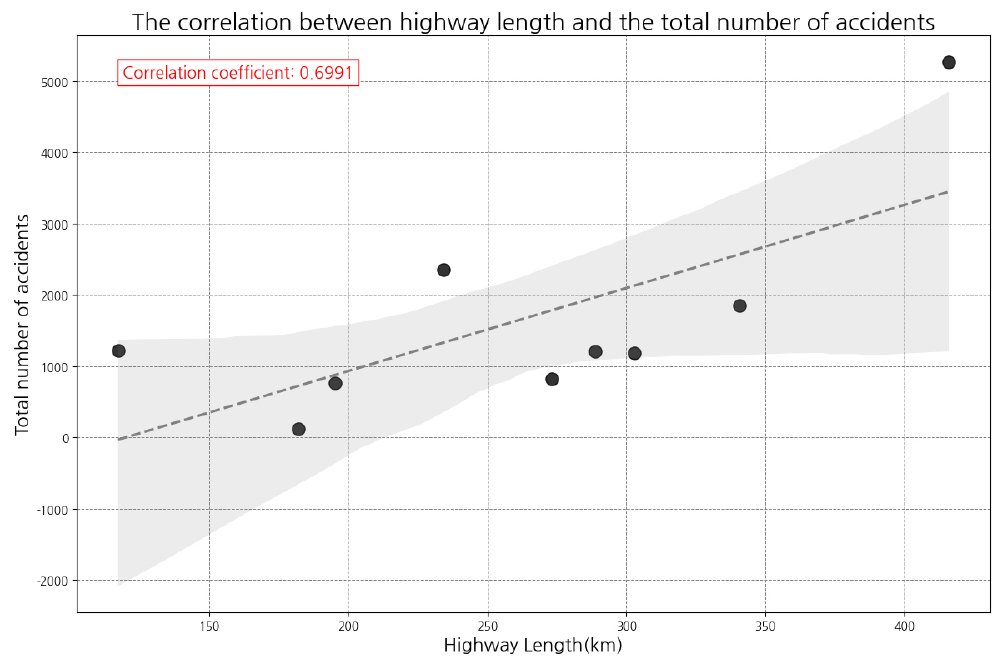
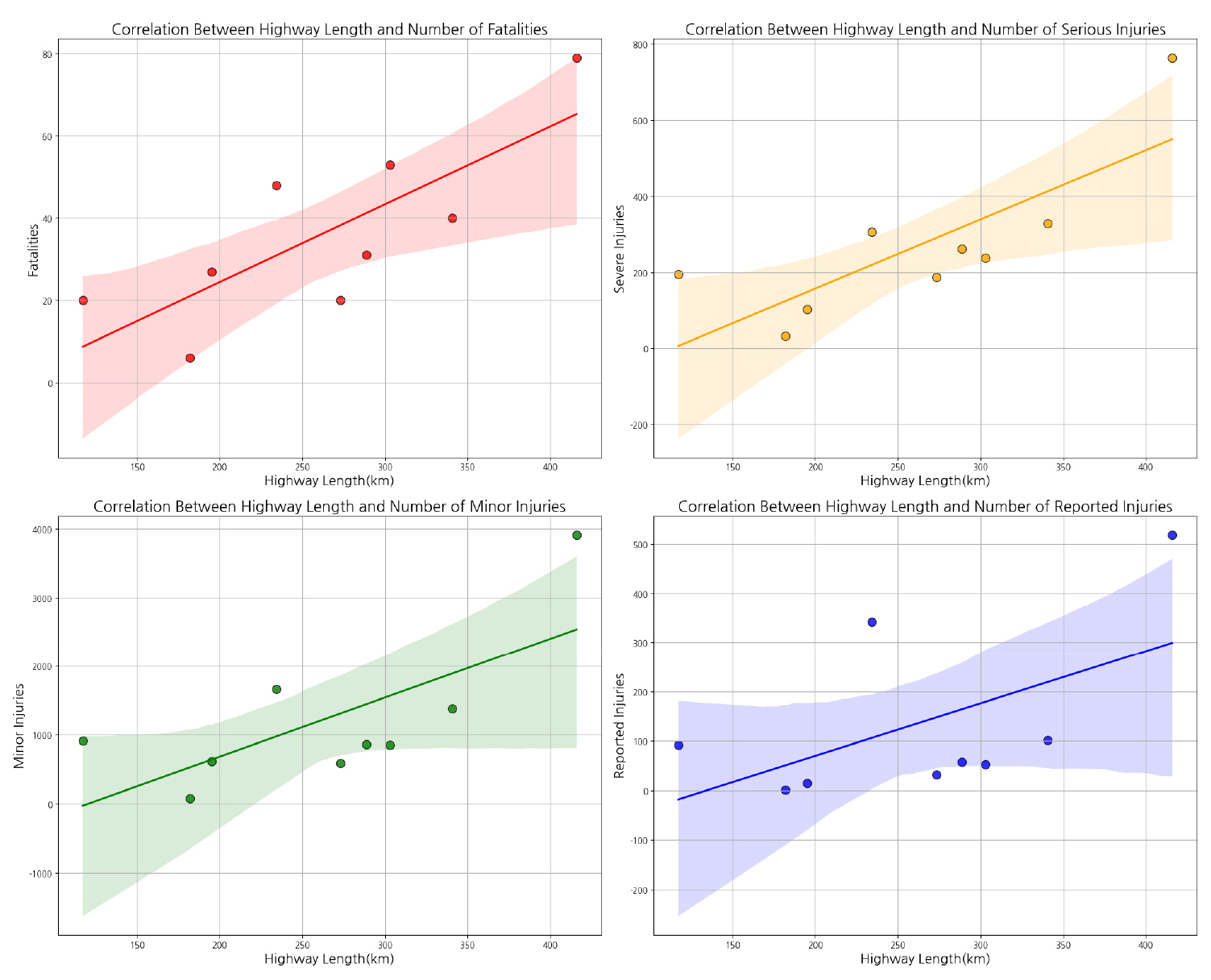
Table 2를 보면, 부상신고자수의 경우, 사고로 인한 인명피해와 직접적인 연관성이 미미하기 때문에 상관계수가 다른 세 변수보다 현저히 낮게 도출되었으며, p-value 또한 기준값인 0.05보다 큰 값이 도출되어 통계적으로 유의미하지 않다는 결과가 나왔다. 따라서 본 연구에서는 부상신고자수를 제외한 사망자수, 중상자수, 경상자수 이 세 가지의 변수들을 이용해 각 변수에 가중치를 부여하여 사고 심각도를 도출하고자 한다.
Table 2.
Correlations and p-Values of Each Variable by Length
| Variable | Correlation Coefficient | p-value |
| Number of Fatalities | 0.7812 | 0.0129 |
| Number of Serious Injuries | 0.7876 | 0.0117 |
| Number of Minor Injuries | 0.6959 | 0.0373 |
| Number of Reported Injuries | 0.5433 | 0.1306 |
2.3 사고심각도 산정
다양한 요인이 존재할 때, 심각한 사고는 어떤 환경과 요인에 의해 이루어지는지를 분석해보고자 사고 심각도를 정의하였다. 사고 심각도는 교통사고가 얼마나 심각한 결과를 초래했는지를 평가하는 기준으로 사용되며, 이는 주로 사고로 인한 부상 상태와 피해 정도를 기준으로 구분된다. 사고의 영향을 보다 체계적으로 분석하고 평가하는 데 사용되는 인자로서 본 연구에서는 데이터 선정 부분에서 유의미한 변수로 도출된 사망자수, 중상자수, 경상자수를 대상으로 사고 심각도를 산정하였다. 각 변수에 대해 일반적인 가중치 비율을 적용하였으며, 날씨나 도로조건에 대한 가중치를 본 연구에서는 따로 고려하지 않고 단순히 인명피해에 대한 가중치만을 적용하였다.
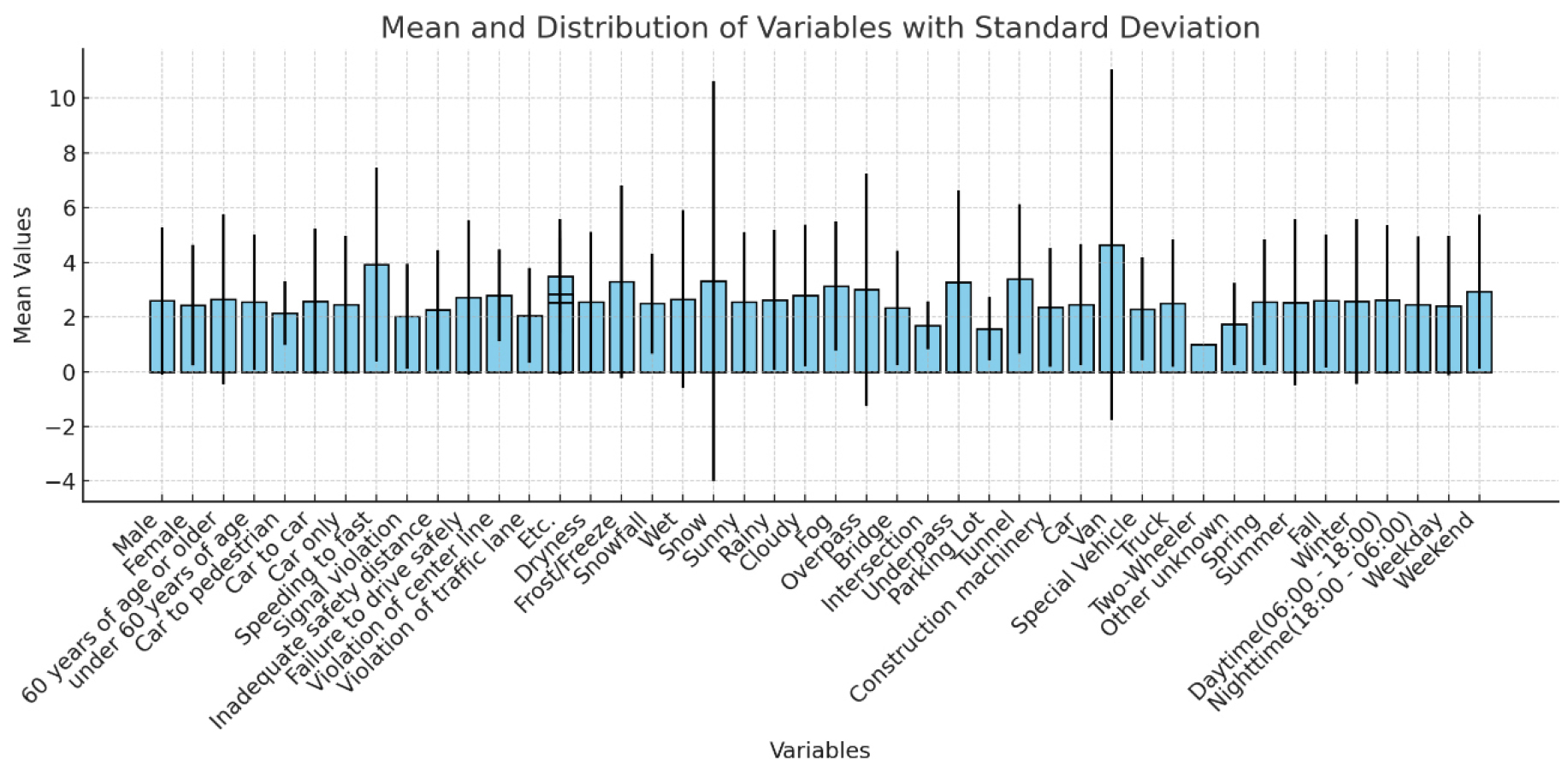
수집한 데이터마다 사고 심각도를 산정한 뒤, 각 변수들을 그룹화하여 Fig. 4와 같이 심각도의 평균과 표준편차를 산정하였다. 심각도의 판단 기준으로는 평균값이 3 이상이면 높은 심각도, 2.5 이상 3 미만이면 중간 심각도, 2.5 미만이면 낮은 심각도로 판단하였다. 표준편차의 경우 값이 크다는 것은 데이터의 변동성이 크다는 의미이며 고속도로 사고의 경우, 표준편차가 클 경우, 매우 다양한 상황에서 사고가 발생한다는 것을 의미한다.
Fig. 4에서 평균값이 3이상인 경우는 결빙, 강설, 안개 등 기후조건과 과속과 같이 일반적으로 알려진 경우와 지하차도 및 터널이라는 도로 형태, 그리고 Van차량인 경우였으며 표준편차가 크게 나타난 경우는 60세 이상 운전자, 과속, 결빙, 강설, 고가 및 지하차도, Van차량, 동절기인 것으로 나타났다.
2.4 머신러닝 알고리즘의 선정
머신러닝은 컴퓨터가 명시적으로 프로그래밍되지 않고도 데이터를 통해 학습하고, 이를 통해 새로운 데이터를 예측하거나 분석할 수 있는 방법을 의미한다. 최근에는 교통사고 및 고속도로 내의 사고에 대해 머신러닝 기법을 활용한 연구가 이루어지는 추세이다.
본 연구에서는 앞선 선행 연구들에 주로 사용된 AdaBoost, XGBoost, Random Forest, SVM 이 네 가지 알고리즘에 대해 수집한 데이터들로부터 고속도로 사고 심각도를 가장 잘 예측하고 구현하는 최적의 알고리즘을 찾고 그에 따른 추후 연구를 실시하였다. 정확도(Accuracy)는 전체 데이터 중 정확하게 분류된 비율을 의미하고 F1-score은 정밀도(Precision)와 재현율(Recall)의 조화 평균으로써 불균형 데이터에서는 더 신뢰할만한 지표이다. 따라서 이 두 가지 지표를 기준으로 네 가지 알고리즘의 성능 평가를 실시하였다. 각 알고리즘의 개념과 작동 방식, 장단점은 Table 3과 같다.
네 가지 알고리즘을 각각 적용하여 Average의 세 가지 옵션인 Micro, Macro, Weighted 중에서 Weighted 방식을 이용하여 F1-score를 산정하였다. Weighted(가중 평균)은 각 클래스의 샘플 수를 가중치로 하여 성과 지표를 평균하는 방식으로 각 클래스의 정밀도, 재현율, F1-score를 계산한 후, 각 클래스의 샘플 수를 반영한 가중치를 곱해 평균을 구하게 되는데, 데이터셋에 클래스 불균형이 있을 때 사용하는 것이 일반적이며 전체 성과를 더 정확하게 반영하고자 할 때 유리하다. Weighted 방식을 통해 도출된 각 옵션에 대한 정확도와 F1-score 값은 Table 4와 같다.
Table 4를 보면, 정확도와 F1-score 모두 고려했을 때 XGBoost 알고리즘 성능이 가장 우수한 것으로 추측된다. 하지만 모델의 성능을 최대한으로 끌어올리고, 적절한 학습이 이루어지도록 하기 위해 본 연구에서는 하이퍼파라미터(Hyperparameter)를 적용하여 재분석을 실시해보고자 하였다.
Table 3.
Algorithm Concepts and Performance Comparison
Table 4.
Comparison of Algorithm Performance by Average Type
3. 하이퍼파라미터(Hyperparameter)를 이용한 머신러닝
하이퍼파라미터는 각 모델의 성능에 직접적인 영향을 미치기 때문에 최적의 설정을 찾는 것이 중요하다. 따라서 각 알고리즘별로 적당한 수의 파라미터를 적용하여 최적의 알고리즘을 도출해보고자 하였다. 각 알고리즘에 적용한 하이퍼파라미터는 다음과 같다.
Table 5를 활용하여 각각 하이퍼파라미터 튜닝을 하였다. 각 학습기는 각 알고리즘의 특성에 맞춘 타당한 범위를 설정해 적용시켰으며, 그 결과는 아래와 같다.
Table 5.
Applied Hyperparameters by Algorithm
| Model | Hyperparameter | ||
| AdaBoost | n_estimators | learning_rate | |
| XGBoost | n_estimators | learning_rate | max_depth |
| Random Forest | n_estimators | max_depth | min_samples_split |
| SVM | kernel | degree | C |
Table 6과 Table 7은 각각의 적용 모델에 대해 결과를 표로 정리하였다. SVM 알고리즘에 대한 결과 값 또한 0.9 이상의 높은 수준을 나타내었으나 앞의 세 알고리즘과 성능이 크게 다르지 않았다.
Table 6.
Application of hyperparameter in AdaBoost
Table 7.
Application of hyperparameter in XGBoost
Table 8에서 max_depth에 None을 설정하는 것은 Random Forest에서 자주 사용하는 방법 중 하나로써, max_depth=None은 트리의 깊이를 제한하지 않고 트리가 리프 노드까지 최대한 성장할 수 있도록 허용한다. 일반적으로 Random Forest의 기본 설정은 max_depth=None으로 되어 있어 각 트리의 복잡도를 최대한으로 증가시키게 된다.
Table 8.
Application of hyperparameter in Random Forest
네 가지 알고리즘을 각각 튜닝한 결과를 종합하여 나타내면 Fig. 5와 같다.
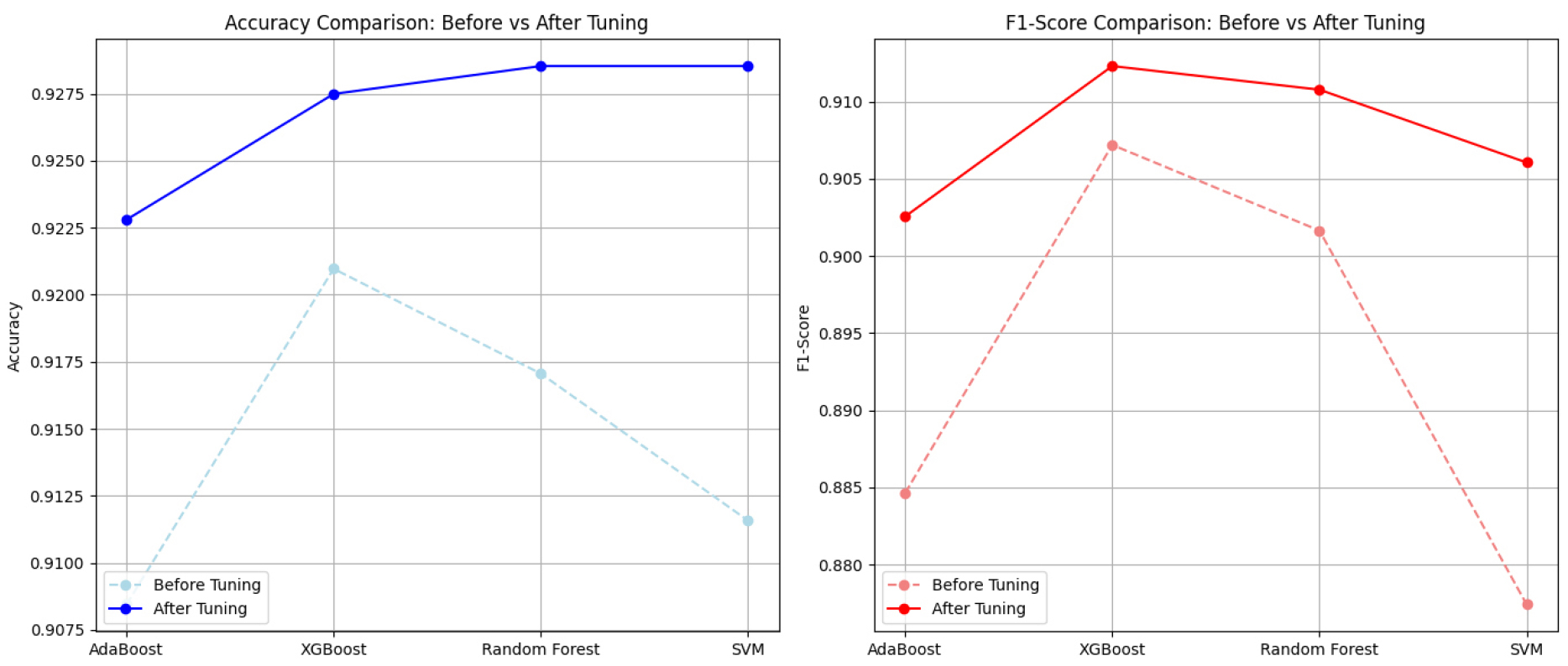
4. 심각도 분석
본 연구에서는 가장 좋은 성능으로 검증된 XGBoost 알고리즘을 활용하여 가해운전자 연령대별 사고 심각도에 영향을 주는 요인들을 도출하였다.
4.1 연령별 사고 심각도 산정
본 연구에서는 가해운전자를 연령에 따라 총 7개의 그룹(20세 이하, 21-30세, 31-40세, 41-50세, 51-60세, 61-64세, 65세 이상)으로 나누었으며 해당 그룹에 대한 사고 수 및 사고 심각도의 평균은 다음과 같다.
사고 심각도 평균 산정시, 데이터의 정규성을 위해 정규화 실시 후에 산정을 하였으며, Table 10에 나타난 바와 같이 사고 심각도 평균이 3이 넘는 가해운전자 연령대는 20세 이하, 41-50세, 61-64세, 65세 이상이며 이 중 20세 이하가 가장 높고 그 다음이 65세 이상이다.
Table 10.
Number of Accidents and Average Severity according to Age-Groups
| Age of Offending Driver | Number of Accident | Average Accident Severity |
| Under 20 | 389 | 3.126 |
| 21-30 | 3373 | 2.805 |
| 31-40 | 3674 | 2.928 |
| 41-50 | 4222 | 3.077 |
| 51-60 | 5017 | 2.995 |
| 61-64 | 1329 | 3.012 |
| Over 65 | 1557 | 3.092 |
4.2 사고 영향 변수 추출
본 연구에서는 각 연령대별로 사고 심각도에 영향을 주는 요소들을 선별하고 연령대별 비교되는 특성을 분석하였다. 본 연구에서는 요일 변수는 고려하지 않았으며, 연령대를 7개로 나눈 후, 각 연령별 상위 5개를 추출하여 총 35개의 변수 중, 전체에 대한 각 항목이 차지하는 비율도 추가로 도출하였다. 그 결과는 Table 11과 같다.
Table 11에서 65세 이상을 대상으로 한 항목별 차지 비율은 Percentage(Elderly)에 기입하였다. 기상상태와 노면상태 항목의 경우 고령층을 대상으로 보았을 때 10% 넘게 증가한 반면, 다른 항목들은 감소하거나 변동이 없는 것으로 나타났다. 이러한 점으로부터 고령 가해운전자의 사고 심각도에 영향을 주는 요인이 기상과 그에 따른 노면상태라고 판단된다. 특히, 고령 가해운전자는 노면상태(적설, 서리/결빙, 젖음/습기) 및 기상 상태(비, 눈)와 같은 환경적 요인에 더 큰 영향을 받는 것으로 나타났다. 즉, 기후로 인한 노면상태의 변동성(블랙아이스, 화이트아웃, 플래시 플러드 등)에 대해 즉각적인 판단을 내리는 것이 부족하고 미끄럼 등의 사고 발생 시 대처 능력이 다른 연령대에 비해 민첩하지 못해서 발생하는 현상이라 볼 수 있다.
법규위반의 영향 또한 존재하지만 운전이 미숙하거나 출퇴근 등의 조건 영향을 많이 받은 젊은 연령대에서 더 크게 작용하는 것으로 보여진다. 즉, 고령 운전자는 기후 조건이 사고 심각도에 중요한 영향을 미치며, 환경 요인에 대한 민감도가 다른 연령대보다 높은 경향이 있다고 할 수 있다.
Table 11.
Accident Impact Variables by Age Group of At-Fault Drivers
5. 결 론
교통사고는 인적, 시설, 환경, 시설 등 다양한 원인에 의해 발생한다. 이러한 원인 분석은 본래 통계학적 방법을 통해 수행되어왔으나, 최근 인공지능에 대한 관심이 높아짐에 따라 머신러닝을 이용한 연구가 증가하고 있다.
본 연구는 고속도로 내에서 발생하는 사고에 대해 이와 같은 환경에서 가장 예측이 뛰어난 알고리즘을 선정하고 이를 사용해 가해운전자 연령대별 사고 심각도에 영향을 주는 변수들을 산출하였다. 이를 위해 머신러닝 알고리즘인 Adaboost, XGBoost, Random Forest, SVM 이 네 가지 알고리즘을 적용하여 이를 비교분석한 결과, XGBoost 알고리즘이 가장 예측이 뛰어남을 보였으며 특히, 하이퍼파라미터 적용으로 성능이 더 좋아졌음을 확인하였다.
선별한 XGBoost 알고리즘을 활용하여 가해운전자 연령대를 7개로 나누어 연령대별 사고 심각도에 영향을 가장 많이 주는 변수를 5개씩 나타낸 결과, 고령 운전자 그룹은 기후 조건, 노면 상태와 같은 환경적 요인에 크게 영향을 받는 것으로 나타났으며 다른 그룹의 경우 과속, 중앙선 침범 등의 법규 위반이 주요 요인으로 나타났다. 이는 각 연령대에 따라 적합한 사고 예방 대책이 필요함을 의미한다. 예를 들어, 고령 운전자를 위한 기상 경보 시스템이나 노면 상태 예측 알림 서비스와 같은 기술적 지원이 효과적일 수 있다. 반면, 젊은 운전자 그룹에는 교통 안전 교육 강화 및 법규 위반에 대한 제재 정책의 개선이 요구된다,
최종적으로 이러한 머신러닝의 이용으로 다양한 자료를 토대로 한 교통사고의 분석이 가능하며 이 연구의 경우에도 수집된 2014~2022년 외의 자료를 추가한다면, 더 정확한 상관관계를 도출할 수 있을 것이라 판단된다.
